Django视图备注
1.限制请求装饰器。推荐一个好用的测试工具Postman。
from django.views.decorators.http import require_http_methods
@require_http_methods(["GET"])
def index(req):
.....
当使用Postman再次使用post请求时,返回的状态为405。
http 中有很多方法,用的时候底层源码看下就行。
2.重定向,分为永久性重定向(301)和暂时性重定向(302),需要注意的是当你反转时格式为app_name:url_name。
>def redirect(to, *args, permanent=False, **kwargs):
...
return redirect(reverse('art:index'))
3.WSGIRequest。Django视图当中的request参数就是WSGIRequest对象(继承至HttpRequest),WSGIRequest并非是浏览器发送给我们的,而是Django接收到浏览器的请求后,根据http请求携带的参数及报文信息创建而成,并作为视图函数的第一个参数传递给函数。
type(req)
<class 'django.core.handlers.wsgi.WSGIRequest'>
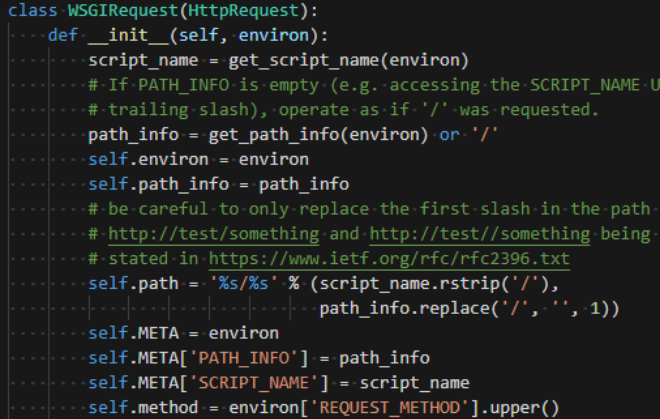
我们可以在里面看到GET,POST(QueryDict),COOKIES,META(客户端发上来的所有header信息),path(请求服务器的完整路径,不包含域名和参数),get_full_path等方法+属性。
for key,value in req.META.items():
print(f"{key}: {value}")
>REMOTE_ADDR:
关于META信息中的REMOTE_ADDR,客户端的ip地址,如果服务器使用了nginx做反向代理或者负载均衡,那么这个值永远只会返回127.0.0.1,这个时候可以使用HTTP_X_FORWARDED_FOR来获取(由于还没实践过反向代理,暂未验证)。
if req.META.has_key('HTTP_X_FORWARDED_FOR'):
ip = req.META['HTTP_X_FORWARDED_FOR']
else:
ip = req.META['REMOTE_ADDR']
另外如HttpRequest的is_secure判断是否为https,is_ajax判断是否为ajax请求(不过看文档似乎3.1即将抛弃此种写法)
warnings.warn(
'request.is_ajax() is deprecated. See Django 3.1 release notes '
'for more details about this deprecation.',
RemovedInDjango40Warning,
stacklevel=2,
)
不过原理应该是一样的,还是判断META请求头里面是否存在键为X-Requested-With,值为XMLHttpRequest的数据,不过目前还没搞清楚HTTP_X_REQUESTED_WITH和X-Requested-With的区别。
4.QueryDict,我们取值最好使用字典的get方法来取值,这样即使相应地键不存在,也会返回None而不是报错。
print(type(req.GET))
<class 'django.http.request.QueryDict'>
设置默认值的用法如下,
req.GET.get('page', default=1)
getlist()方法,用于获取同一个key对应的多个值,例如在前端checkbox中,经常会有多个选项,假如name=‘key’那么用户如果勾选了多个值,后端可使用getlist来拿到完整的值组成的列表。
5.HttpResponse对象。和HttpRequest相反,视图层处理完相关逻辑后,必须返回一个HttpResponseBase或其子类的相应给浏览器。其常用属性为content,status_code,content_type(返回数据的MIME类型,默认为text/html,如果是text/plain那么会显示一个纯文本,multipart/form-data为文件提交,application/json为JSON数据格式),设置请求头,如respone['X-Access-Token']='****';
respone = HttpResponse()
respone.content = '<h1>123</h1>'
status_code = 200 # HttpResponseBase类属性默认
respone.status_code = 400
# content_type
HttpResponse(content='<h1>123</h1>', content_type='text/plain')
# 设置请求头
respone['fire'] = 'zhangxiaofei'
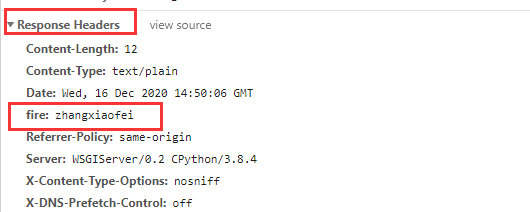
常用方法有set_cookie,delete_cookie,write(HttpResponse是一个类似文件的对象,可以写入数据到数据体中,即content中)
6.JsonResponse,HttpResponse的子类。了解JsonResponse之前,我去学习了python关于操作json的常用方法,常用有4种,即dumps(将 Python 对象编码成 JSON 字符串),loads(将已编码的 JSON 字符串解码为 Python 对象),dump(主要用于将数据写成json文件)和load(相反),还是比较好理解的。
fire = {'name':'zhangxiaofei', 'age':18}
f = json.dumps(fire)
>{"name": "zhangxiaofei", "age": 18}
json.loads(f)
> {'name': 'zhangxiaofei', 'age': 18}
如果不使用JsonResponse,我们传递一个json格式的数据常规方法如下:
fire = {'name':'zhangxiaofei', 'age':18}
fire_str = json.dumps(fire)
response = HttpResponse(fire_str, content_type = 'Application/json')
而使用JsonResponse,其默认接受一个字典,除非增加safe=False参数,
fire = {'name':'zhangxiaofei', 'age':18}
response = JsonResponse(data = fire, safe=False)
# :param safe: Controls if only ``dict`` objects may be serialized.
# Defaults to ``True``
7.较小csv文件的下载。我们可以采取一次性将数据返回给浏览器。
# 首先设置content_type类型
resp = HttpResponse(content_type ='text/csv')
# 设置请求头,配置文件 以附件下载,并命名
resp['Content-Disposition'] = "attachment; filename=fire.csv"
# 为何可以写成这种,我们可以对比with open('xx') as fp
# csv.writer(fp) 是往xx中增加内容,而HttpResponse下面
# 也有write方法
writer = csv.writer(resp)
writer.writerow(['name', 'age'])
writer.writerow(['fire', 18])
如何通过一个模板文件来开启csv文件的下载?模板的好处在于将数据和数据处理的格式完全分开,互不干扰,看个人习惯。
# views.py
# 通过loader可导入模板
from django.template import loader
def index6(req):
resp = HttpResponse(content_type ='text/csv')
resp['Content-Disposition'] = "attachment; filename=fire.csv"
context = {
'rows': [
['name','fire'],
['age',18]
]
}
templates_name = loader.get_template('temp_test.txt')
csv_temp = templates_name.render(context = context)
resp.content = csv_temp
return resp
# temp_test.txt 模板里的空格换行会反映在csv文件中
{% for row in rows%}{{row.0}}, {{row.1}}
{% endfor %}
8.利用StreamingHttpResponse处理较大的csv文件(当然文件较大和较大这个有点玄学,看个人感觉)。为什么需要单独拉出来讲,如果文件较大,服务器处理时间较长,在客户端这边是没有任何响应的,每个浏览器都有自己默认的超时时间,如果长时间没响应浏览器可能会判断客户端这个请求是失败的。StreamingHttpResponse继承至HttpResponseBase,接收一个streaming_content(可迭代的对象,我的理解是可以用for循环取出的值),翻阅源码,我们可以看见如果调用content方法会raise AttributeError,并建议使用"`streaming_content` instead.",没有write方法。
resp = StreamingHttpResponse(content_type = "text/csv")
resp['Content-Disposition'] = "attachment; filename=large.csv"
# 定义一个巨大for循环
rows = (f"{row}, {row}\n" for row in range(0, 10000000))
resp.streaming_content = rows
上面的rows=(for in),python中用圆括号包裹的for in产生的是一个生成器,其中遍历循环产生的数据并不会一次性全部返回,而是当每次执行它的时候它才会返回一条数据(yield)给你,先遍历range(0, 10000000),然后将取到的row 返回给前面。可以看到没有丝毫迟疑就开始下载,如果是采用HttpResponse的方法会响应半天才下载。
当然,StreamingHttpResponse会保持服务器和客户端的连接,比较消耗服务器的资源,尽量少用。
关于for循环的便捷写法如下:
[row for row in range(0, 10)] > [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 约等价于(因为上面的迭代必须放在元组或者列表中)
for row in range(0, 10):
return row
9.类视图。在我们创建Django项目时,打开urls.py文件,可以看到里面有三种例子,分别为Function views,Class-based views,Including another URLconf,类视图必须继承至django.views.generic.base.View,用来写get和post请求视图会非常便捷。
class Fire(View):
def get(self,req,detail_id):
return HttpResponse(f'get:{detail_id}')
def post(self,req):
return HttpResponse('post')
需要注意的是,当你用类视图只定义了get方法而没有定义post方法,而刚好有人使用了post方法来请求,那么Django会默认的将其丢给http_method_not_allowed来处理。
# def post(self,req):
# return HttpResponse('post')
def http_method_not_allowed(self, req):
return HttpResponse('content-http_method_not_allowed')
使用postman来进行post测试,当写了http_method_not_allowed方法时,用户使用post方法,状态码返回200,并返回content-http...,但如果没有这个方法,使用post请求,将会返回405(请求方法不允许)。
另外,无论是get或者post,Django都会默认先走View下的dispatch方法,测试如下:
class Fire(View):
def get(self,req):
print("get")
return HttpResponse('get')
def dispatch(self, request, *args, **kwargs):
print("dispatch")
return super().dispatch(request, *args, **kwargs)
10.TemplateView,和View处于同一个导入路径,专门用于返回一个静态页面,可以不用经过视图函数层。例如:关于我们,这些基本不会变动而且没有任何参数的页面,建议直接在urls.py中引用。
# urls.py
### generic 中的__all__属性可以直接导出TemplateView
from django.views.generic import TemplateView
# TemplateResponseMixin规定必须要传template_name
# Mixin的多重继承含义可以去了解下
urlpatterns = [
path('about/', TemplateView.as_view(template_name ='about.html')),
]
如果想要引用参数,也是可以的,about.html可以获取my_name参数,如下:
# views.py
class About(TemplateView):
template_name = 'about.html'
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context["my_name"] = 'zhangxiaofei'
return context