ListView,快速实现数据列表页。数据库里面填充了100条数据,示例代码如下:
from django.views.generic import ListView
class ListTest(ListView):
# 引用的模型名称
model = Article
# 引用的模板
template_name = 'Article-Test.html'
# 一页多少条数据
paginate_by = 10
# 上下文名称,即模板中调用的变量
context_object_name = 'my_articles'
# 排序规则
ordering = '-pk'
# 翻页参数
page_kwarg = 'p'
ListView类会调用get_context_data方法,所以如果我们还想传递上下文,可以在此方法中先获取父类的context,再增加自己想要的内容(这是因为如果不先调用父类,那么很多参数我们就用不了);get_queryset会默认使用all()返回所有的queryset,我们也可以进行修改,过滤掉自己不想要的数据,但是我在测试这个方法的时候,命令行提示Pagination may yield inconsistent results with an unordered object_list,我就很奇怪,明明上面定义了ordering,怎么会没有排序呢?
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context["user_name"] = 'fire'
print("*"*30)
for i,v in context.items():
print(str(i) + ': '+str(v))
print("*"*30)
return context
def get_queryset(self):
# return super().get_queryset()
return Article.objects.filter(pk__lte=95)
我看了下源码,如下,确实是获取到了排序规则的
ordering = self.get_ordering() # -pk
if ordering:
if isinstance(ordering, str): # yes
ordering = (ordering,)
queryset = queryset.order_by(*ordering)
return queryset
再仔细看了下自己写的代码,悟了,里面唯一的区别在于我没有继承django自身get_queryset的方法,换一种写法就可以了
return super().get_queryset().filter(pk__lte =10)
super().get_queryset()是一个queryset对象,或者不想继承django自身的方法,自己在Article.objects.filter(pk__lte=95)后面跟上排序的order规则也可以。
在ListView的get_context_data方法中,context对象中的paginator和page_obj会经常使用,二者的导出路径均在django.core.paginator下,paginator对应的类是Paginator,常用方法num_pages,取得总页数,page_range取得页数范围值,count取得总条数,需要注意的是,该项针对的是你在get_queryset中所筛选出的数据,例如,当你设置了pk__lte =10,那么count只会取得pk__lte =10满足的数据条目!其中page_obj对应的是Page类,主要有has_next,has_previous,previous_page_number,number(当前页),next_page_number,start_index(获取当页第一条数据下标,即在总列表中第几条索引),end_index。
如下利用Bootstrap和ListView快速实现普通分类页

其中模板页面利用paginator和page_obj的一些属性,判断链接跳转,以及是否存在第一页/最后一页以禁止点击。源代码如下:
# Article-List.html
<ul>
{% for article in my_arts %}
<li>{{article.title}}</li>
{% endfor %}
</ul>
<ul class="pagination">
{# 上一页 #}
{% if not page_obj.has_previous %}
<li class='disabled'><a href="javascript:void(0)" >上一页</a></li>
{% else %}
# 两种写法任选其一
{% comment %} <li><a href="?p={{page_obj.previous_page_number}}" >上一页</a></li> {% endcomment %}
<li><a href="{% url 'front:index' %}?p={{page_obj.previous_page_number}}">上一页</a></li>
{% endif %}
{# 中间页 #}
{% for index in paginator.page_range %}
{% if index == page_obj.number %}
<li class='active'>
{% else %}
<li>
{% endif %}
<a href="?p={{index}}">{{index}}</a></li>
{% endfor %}
{# 下一页 #}
{% if not page_obj.has_next %}
<li class='disabled'><a href="javascript:void(0)" >下一页</a></li>
{% else %}
<li><a href="?p={{page_obj.next_page_number}}" >下一页</a></li>
{% endif %}
</ul>
但是这个翻页有一个问题,就是展示了所有的分页,一旦数据有成千上万条,那翻页的摆放就懵逼了,所以我们可以再更新一下翻页的代码,如下:
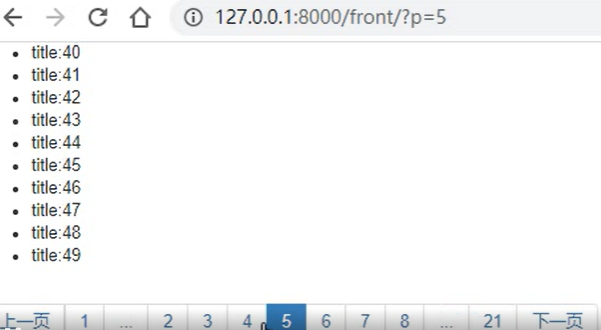
可以看到,前端页面仅显示了当前选中页面的左右两边各三页的链接,前后各增加第一页和最后一页的链接,中间全部用省略号代替,前端html页面和后端视图代码如下:
# articles.html
{# 上一页 #}
{% if not page_obj.has_previous %}
<li class='disabled'><a href="javascript:void(0)">上一页</a></li>
{% else %}
<li><a href="{% url 'front:index' %}?p={{page_obj.previous_page_number}}">上一页</a></li>
{% endif %}
{# 中间的页数处理#}
{% if left_has_more %}
<li><a href="{% url 'front:index' %}?p=1">1</a></li>
<li><a href="javascript:void(0)">...</a></li>
{% endif %}
{% for left_page in left_pages %}
<li><a href="{% url 'front:index' %}?p={{left_page}}">{{left_page}}</a></li>
{% endfor %}
{# 当前页#}
<li class='active'><a href="javascript:void(0)">{{current_page}}</a></li>
{% for right_page in right_pages %}
<li><a href="{% url 'front:index' %}?p={{right_page}}">{{right_page}}</a></li>
{% endfor %}
{% if right_has_more %}
<li><a href="javascript:void(0)">...</a></li>
<li><a href="{% url 'front:index' %}?p={{num_pages}}">{{num_pages}}</a></li>
{% endif %}
{# 下一页 #}
{% if not page_obj.has_next %}
<li class='disabled'><a href="javascript:void(0)">下一页</a></li>
{% else %}
<li><a href="{% url 'front:index' %}?p={{page_obj.next_page_number}}">下一页</a></li>
{% endif %}
视图层:
class ListClass(ListView):
template_name = 'articles.html'
model= Article
page_kwarg = 'p'
paginate_by = 10
ordering = 'pk'
context_object_name = "my_articles"
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
res = self.getPaginationInfo(context['paginator'], context['page_obj'])
context.update(res)
return context
def getPaginationInfo(self, paginator, page_obj, around_page=3):
current_page = page_obj.number
left_has_more = False
right_has_more = False
if current_page - around_page > 1:
left_pages = range(current_page - around_page, current_page)
left_has_more = True
else:
left_pages = range(1, current_page)
if current_page + 1 + around_page > paginator.num_pages:
right_pages = range(current_page + 1, paginator.num_pages + 1)
else:
right_pages = range(current_page + 1, current_page + around_page + 1)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page':current_page,
'left_has_more':left_has_more,
'right_has_more':right_has_more,
'num_pages':paginator.num_pages
}
实现原理也很简单,就是利用paginator和page_obj的一些属性,函数,通过getPaginationInfo新增的around_page参数进行比较,只要当前页比around_page大1,那么说明左边肯定至少有around_page+1条数据,右边的处理也是同理。