最近经常可以在日志中看到一些404页面,一开始以为这些路径都是搞鬼的,但实际反查IP才发现并不是,很多都是正儿八经的搜索引擎爬虫,我把他们分为两类,一种可以采用直接的解码来处理,
例如:
- 假设其现在的编码为windows-1252,需要解码成utf-8
keywords ="广水市大视觉高端婚纱摄影店"
bytes(keywords,'windows-1252').decode('utf-8')
=>'广水市大视觉高端婚纱摄影店'
- 假设其现在的编码为windows-1252,需要解码成utf-8
keywords = bytes(keywords,'iso-8859-1').decode('utf-8')
另外一种比较复杂一些,乱码的内容举例如下
keywords=\xC3\xA8\xC2\xA8\xC2\xBA\xC3\xA6\xE2\x80\xB0\xE2\x82\xAC\xC3\xA7\xE2\x84\xA2\xC2\xBB\xC3\xA8\xC2\xA8\xCB\x9C\xC3\xA5\xE2\x80\x9C\xC2\xA1%20(\xC3\xA5\xE2\x80\xA6\xC6\x92\xC3\xA6\xC5\x93\xE2\x80\x94)
keywords=\xC3\xA8\xC2\xA1\xC5\x92\xC3\xA6\xE2\x80\x9D\xC2\xBF\xC3\xA5\xE2\x80\xA6\xC2\xBC\xC3\xA6\xC5\x93\xC6\x92\xC3\xA8\xC2\xA8\xCB\x86\xC3\xA4\xC2\xB8\xC2\xBB\xC3\xA7\xC2\xAE\xC2\xA1
keywords=\xC3\xA6\xC5\xBD\xC2\xA8\xC3\xA6\xE2\x80\xB9\xC2\xBF\xC3\xA5\xC2\xB8\xC2\xAB
keywords=\xC3\xA6\xC2\xB1\xC2\xBD\xC3\xA8\xC2\xBB\xC5\xA0\xC3\xA8\xC2\xA3\xC5\x93\xC3\xA5\xC2\xB8\xC2\xAB\xC3\xA5\xC2\xB8\xC2\xAB\xC3\xA5\xE2\x80\x9A\xE2\x80\xA6
keywords=\xC3\xA6\xC2\xA9\xC5\xB8\xC3\xA5\xC2\xA0\xC2\xB4\xC3\xA6\xC2\xB2\xC2\xB9\xC3\xA7\xC2\xAB\xE2\x84\xA2\xC3\xA5\xC2\xA4\xC5\x93\xC3\xA6\xE2\x80\xBA\xC2\xB4\xC3\xA5\xC5\xA0\xC2\xA0\xC3\xA6\xC2\xB2\xC2\xB9\xC3\xA5\xE2\x80\x9C\xC2\xA1
keywords=\xC3\xA5\xCB\x86\xE2\x80\xA0\xC3\xA5\xE2\x80\xB0\xC2\xB2\xC3\xA5\xC2\xAD\xC2\xB8\xC3\xA5\xC2\xBE\xE2\x80\x99
keywords=\xC3\xA5\xC2\xB9\xC2\xAB\xC3\xA5\xC2\xBB\xC5\xA1
keywords=\xC3\xA5\xC2\xAF\xC2\xAB\xC3\xA5\xC2\xAD\xE2\x80\x94\xC3\xA6\xC2\xA8\xE2\x80\x9C\xC3\xA6\xC2\xB8\xE2\x80\xA6\xC3\xA6\xC2\xBD\xE2\x80\x9D\xC3\xA5\xE2\x80\x9C\xC2\xA1%20(\xC3\xA5\xC2\xAE\xC2\xA4\xC3\xA5\xE2\x80\xA6\xC2\xA7)
keywords=\xC3\xA5\xC2\xA4\xE2\x80\x93\xC3\xA5\xE2\x80\xB9\xC2\xA4\xC3\xA6\xC5\xB8\xC2\xA5\xC3\xA8\xC2\xB2\xC2\xA8\xC3\xA5\xE2\x80\x9C\xC2\xA1
keywords=\xC3\xA5\xC2\xA4\xC5\x93\xC3\xA6\xE2\x80\xBA\xC2\xB4\xC3\xA5\xC2\xA4\xE2\x80\x93\xC3\xA8\xC2\xB3\xC2\xA3\xC3\xA5\xC2\xBA\xE2\x80\x94\xC3\xA5\xC2\xBA\xE2\x80\x94\xC3\xA5\xE2\x80\xB9\xE2\x84\xA2\xC3\xA5\xE2\x80\x9C\xC2\xA1
keywords=\xC3\xA5\xC2\xA4\xC5\x93\xC3\xA6\xE2\x80\xBA\xC2\xB4\xC3\xA4\xC2\xB8\xC2\xBB\xC3\xA4\xC2\xBB\xC2\xBB
keywords=\xC3\xA4\xC2\xBF\xC2\xA1\xC3\xA8\xE2\x84\xA2\xC5\xB8\xC3\xA7\xC2\xB3\xC2\xBB\xC3\xA7\xC2\xB5\xC2\xB1\xC3\xA7\xC2\xB6\xC2\xAD\xC3\xA4\xC2\xBF\xC2\xAE\xC3\xA6\xC5\xA0\xE2\x82\xAC\xC3\xA8\xC2\xA1\xE2\x80\x9C\xC3\xA5\xE2\x80\x9C\xC2\xA1
可以先将其解码成utf-8,再将其解码后的结果当做windows-1252编码,再解码成utf-8,实际操作如下:
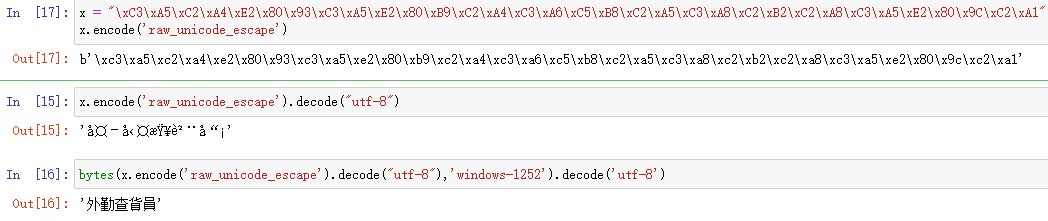
x = "\xC3\xA5\xC2\xA4\xE2\x80\x93\xC3\xA5\xE2\x80\xB9\xC2\xA4\xC3\xA6\xC5\xB8\xC2\xA5\xC3\xA8\xC2\xB2\xC2\xA8\xC3\xA5\xE2\x80\x9C\xC2\xA1"
x.encode('raw_unicode_escape')
=>b'\xc3\xa5\xc2\xa4\xe2\x80\x93\xc3\xa5\xe2\x80\xb9\xc2\xa4\xc3\xa6\xc5\xb8\xc2\xa5\xc3\xa8\xc2\xb2\xc2\xa8\xc3\xa5\xe2\x80\x9c\xc2\xa1'
x.encode('raw_unicode_escape').decode("utf-8")
=>'外勤查貨員'
bytes(x.encode('raw_unicode_escape').decode("utf-8"),'windows-1252').decode('utf-8')
=>'外勤查貨員'
上面的测试在jupyter notebook中是可行的,
但在实际的django项目中出现了一些问题,例如在将字符串转为bytes的过程中(keywords.encode('raw_unicode_escape')),产生了两个反斜杠,导致再解码为utf-8时又被复原,根本没有实际作用,使用replace函数也无法剔除,例如:
keywords = '\xC3\xA6\xC2\xA5\xC2\xAD\xC3\xA5\xE2\x80\xB9\xE2\x84\xA2\xC3\xA7\xE2\x84\xA2\xC2\xBC\xC3\xA5\xC2\xB1\xE2\x80\xA2\xC3\xA7\xC2\xB8\xC2\xBD\xC3\xA7\xE2\x80\xBA\xC2\xA3'
# str to bytes
a = keywords.encode('raw_unicode_escape')
=>b'\\xC3\\xA6\\xC2\\xA5\\xC2\\xAD\\xC3\\xA5\\xE2\\x80\\xB9\\xE2\\x84\\xA2\\xC3\\xA7\\xE2\\x84\\xA2\\xC2\\xBC\\xC3\\xA5\\xC2\\xB1\\xE2\\x80\\xA2\\xC3\\xA7\\xC2\\xB8\\xC2\\xBD\\xC3\\xA7\\xE2\\x80\\xBA\\xC2\\xA3'
# bytes to utf-8 str
a.decode("utf-8")
=>'\xC3\xA6\xC2\xA5\xC2\xAD\xC3\xA5\xE2\x80\xB9\xE2\x84\xA2\xC3\xA7\xE2\x84\xA2\xC2\xBC\xC3\xA5\xC2\xB1\xE2\x80\xA2\xC3\xA7\xC2\xB8\xC2\xBD\xC3\xA7\xE2\x80\xBA\xC2\xA3'
查到一篇博客,介绍了解决办法如下:
a = keywords.encode('raw_unicode_escape')
b = a.decode('unicode-escape').encode('ISO-8859-1')
keywords_xc = bytes(b.decode("utf-8"),'windows-1252').decode('utf-8')
=>業務發展總監
这个问题的关键之处在于多出的那个反斜杠,解决掉就好了。
目前还没找到形成的原因,先记录解决的办法,后续再来补充。
再发现一种,示例如下
x="\xE5\xB1\x8B\xE8\x8B\x91\xE5\xAE\xA2\xE6\x88\xB7\xE6\x9C\x8D\xE5\x8A\xA1\xE4\xB8\xBB\xE4\xBB\xBB"
x="\xE6\x8A\x80\xE8\xA1\x93\xE5\x93\xA1/\xE6\x8A\x80\xE5\xB7\xA5(\xE5\x8C\x97\xE8\xA7\x92)"
x="\xE8\x91\xB5\xE6\xB6\x8C\xE6\xB8\x85\xE6\xBD\x94\xE5\x93\xA1"
转成二进制后,再转成utf-8编码就可以
x.encode('raw_unicode_escape')
=>b'\xe8\x91\xb5\xe6\xb6\x8c\xe6\xb8\x85\xe6\xbd\x94\xe5\x93\xa1'
x.encode('raw_unicode_escape').decode("utf-8")
=>'葵涌清潔員'
新的乱码日志
%5CxC3%5CxA5%5CxC2%5CxB9%5CxC2%5CxBC%5CxC3%5CxA7%5CxC2%5CxA8%5CxC5%5CxA1%5CxC3%5CxA5%5CxC5%5Cx93%5CxE2%5Cx80%5Cx99%5CxC3%5CxA6%5CxC2%5CxB8%5CxE2%5Cx80%5CxA6%5CxC3%5CxA%206%5CxC2%5CxBD%5CxE2%5Cx80%5Cx9D%5CxC3%5CxA5%5CxE2%5Cx80%5Cx9C%5CxC2%5CxA1/%5CxC3%5CxA6%5CxC2%5CxA0%5CxC2%5CxA1%5CxC3%5CxA5%5CxC2%5CxB7%5CxC2%5CxA5
这个%5C其实就是反斜杠,并且这个乱码中间还夹杂了空格%20,处理方法:先将其解码成常规url格式,再去掉空格%20,再使用之前的方法来处理
a = "%5CxC3%5CxA5%5CxC2%5CxB9%5CxC2%5CxBC%5CxC3%5CxA7%5CxC2%5CxA8%5CxC5%5CxA1%5CxC3%5CxA5%5CxC5%5Cx93%5CxE2%5Cx80%5Cx99%5CxC3%5CxA6%5CxC2%5CxB8%5CxE2%5Cx80%5CxA6%5CxC3%5CxA%206%5CxC2%5CxBD%5CxE2%5Cx80%5Cx9D%5CxC3%5CxA5%5CxE2%5Cx80%5Cx9C%5CxC2%5CxA1/%5CxC3%5CxA6%5CxC2%5CxA0%5CxC2%5CxA1%5CxC3%5CxA5%5CxC2%5CxB7%5CxC2%5CxA5"
from urllib.parse import unquote
# 解码成常规格式,并去掉空格
b= unquote(a, 'utf-8').replace(" ","")
b
=>'\\xC3\\xA5\\xC2\\xB9\\xC2\\xBC\\xC3\\xA7\\xC2\\xA8\\xC5\\xA1\\xC3\\xA5\\xC5\\x93\\xE2\\x80\\x99\\xC3\\xA6\\xC2\\xB8\\xE2\\x80\\xA6\\xC3\\xA 6\\xC2\\xBD\\xE2\\x80\\x9D\\xC3\\xA5\\xE2\\x80\\x9C\\xC2\\xA1/\\xC3\\xA6\\xC2\\xA0\\xC2\\xA1\\xC3\\xA5\\xC2\\xB7\\xC2\\xA5'
# 两个反斜杠转为一个
c = b.encode('raw_unicode_escape').decode('unicode-escape').encode('ISO-8859-1')
c
=>b'\xc3\xa5\xc2\xb9\xc2\xbc\xc3\xa7\xc2\xa8\xc5\xa1\xc3\xa5\xc5\x93\xe2\x80\x99\xc3\xa6\xc2\xb8\xe2\x80\xa6\xc3\xa6\xc2\xbd\xe2\x80\x9d\xc3\xa5\xe2\x80\x9c\xc2\xa1/\xc3\xa6\xc2\xa0\xc2\xa1\xc3\xa5\xc2\xb7\xc2\xa5'
# 编码成utf-8格式,再将其当做windows-1252编码转成二进制再解码成utf-8
bytes(c.decode("utf-8"),'windows-1252').decode('utf-8')
=>'幼稚園清潔員/校工'
参考:
# Python-String to Bytes conversion. Double BackSlash issue [duplicate]
https://stackoverflow.com/questions/33257875/python-string-to-bytes-conversion-double-backslash-issue
# 编码
https://blog.csdn.net/qq_33876553/article/details/79730246