终于利用logstash完成了数据的同步测试,赶紧记录一篇,整个流程运行在1核2G内存云服务器上,最高占用cpu的50%,平均cpu消耗大概在20%~30%左右;mysql添加字段es也可以同步添加,只不过类型为自判断,而且需要mysql中添加新数据时才会将字段同步过去,而在mysql中删除字段是无法同步到es中的,所以字段需慎加;每过5秒mysql的数据会通过logstash的管道同步一次至ES,由于我对数据实时性要求不高,所以够用了;elasticsearch与logstash均为最新版本7.12,接下来我会将云服务器完全格式化掉,再重新走一遍流程。
由于整个服务器都格式化了,所以很多东西都要重新安装。
- nginx,配置文件覆盖,重启
- 启用防火墙,开启80端口方便测试
- 安装mariadb数据库,创建远程连接用户,开启3306端口方便远程访问利用mysqldump将备份的数据库(200万条数据)导入数据库备用
- 安装lrzsz,方便文件传输
- 安装python,用之前备份的requirements.txt(一份虚拟环境,一份服务器环境)导入相关库,其中虚拟环境virtualenvwrapper如果提示pbr相关错误,可参考Django框架搭建的网站上线小测试。
- 项目上传至服务器opt目录,解压
- 安装elasticsearch,logstash,由于我的是1核2G服务器,如果同时启动es和logstash,服务器一下子就崩了,所以修改其占用内存大小,官方建议在jvm.options.d中创建配置文件,由于时间关系,我就直接在二者的jvm.options中修改了Xms和Xmx,启动elasticsearch
- 如果不小心使用root用户启动了elasticsearch,记得重新chown给es,另外建议使用watch观察下es,因为服务器配置原因,经常会在后台崩溃掉。
准备工作基本就到这里。
由于之前只了解过一些elasticsearch,关于logstash并没有使用过,所以又去学习了下logstash的用法,安装方法按照官网的YUM方案或者使用wget方法安装都可以。
以下基本是官网的内容,概念最好记熟,否则资料都不好查。
Logstash管道具有两个必需的元素,即输入input和输出output,以及一个可选的元素,即过滤器filter。输入插件input plugins使用来自源的数据,过滤器插件filter plugins根据您的指定修改数据,输出插件output plugins将数据写入目标。
比较常见的input有file、syslog、redis和beats;而常用的过滤器filter有grok(解析和构造任意文本。Grok是Logstash中将非结构化日志数据解析为结构化和可查询内容的最佳方法。Logstash内置120种样式),mutate(对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段),drop(完全删除事件,例如调试事件),clone(复制事件,添加或删除字段),geoip(geoip:添加有关IP地址地理位置的信息,类似于之前goaccess中使用的geoip库);output主要有elasticsearch,file,graphite,statsd。
第一次启动(苹果电脑第一次运行会有些问题,参考官网解决方案),-e参数指定直接从命令行读取指定配置,可以看到这里面的input和output分别读取标准输入stdin和标准输出stdout:
./bin/logstash -e 'input { stdin { } } output { stdout {} }'
可能会提示如下信息,升级jdk就可以:
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release
如果提示下方pipelines.yml文件也不用管:
Ignoring the 'pipelines.yml' file because modules or command line options are specified
等待一会,可以看到启动了
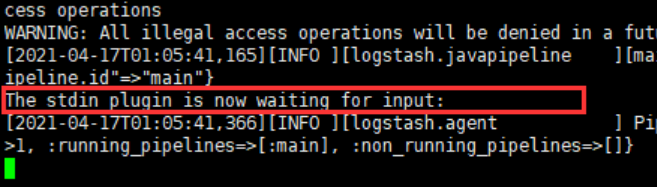
输入helloworld
官方还给出了一个利用filebeat和logstash分析日志到es的示例,因为我已经操作过两遍,就不写了,毕竟这不是重点,只要知道logstash配置方式就可以了
如下两种方式可以帮你测试配置文件是否正确和自动重新加载配置文件,-f参数为指定配置文件:
bin/logstash -f first-pipeline.conf --config.test_and_exit
bin/logstash -f first-pipeline.conf --config.reload.automatic
如何使用logstash同步mysql数据库的数据到es呢?先贴上我的logstash配置代码,一步步解释
input {
jdbc {
jdbc_driver_library => "/usr/src/mysql-connector-java-8.0.23/mysql-connector-java-8.0.23.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/NBA"
jdbc_user => "root"
jdbc_password => "root"
jdbc_paging_enabled => true
jdbc_page_size => "50"
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(update_time) AS unix_ts_in_secs FROM nba_test WHERE (UNIX_TIMESTAMP(update_time) > :sql_last_value AND update_time < NOW()) ORDER BY update_time ASC"
}
}
filter {
ruby {
code => "
event.set('Participation_date', event.get('Participation_date').time.localtime + 8*60*60)
event.set('Retirement_date', event.get('Retirement_date').time.localtime + 8*60*60)
"
}
mutate {
copy => { "number" => "[@metadata][_id]"}
remove_field => ["unix_ts_in_secs"]
#用mutate插件先转换为string类型,gsub只处理string类型的数据,在用正则匹配,最终得到想要的日期
convert => {
"Participation_date"=> "string"
"Retirement_date"=> "string"
}
gsub => ["Participation_date", "T([\S\s]*?)Z", ""]
gsub => ["Retirement_date", "T([\S\s]*?)Z", ""]
}
}
output {
stdout { codec => "rubydebug"}
elasticsearch {
index => "nba20210413"
document_id => "%{[@metadata][_id]}"
}
}
首先可以看到还是固定的三个大参数,input,filter和output,input负责从我的数据库里面提取相关符合条件的数据,filter负责将我的数据进行处理,而output则输出相关数据到界面和elasticsearch。
建议最好按照下方参阅第一篇先进行操作下,有不懂的记下来,再去找答案,会好理解一些。
先来看下input字段,它产生了一个jdbc事件(events),这个jdbc事件有着下面几个属性(properties),在logstash中把它们称之为字段(fields),可以在官方文档右侧的Input plugins->jdbc找到相关的介绍,担心翻译的有问题,于是先将官网对jdbc的定义截图一张如下

“创建此插件是为了从任何具有JDBC接口的数据库中提取数据并导入Logstash。您可以使用cron语法(译者注:类比linux下的crontab)定期计划获取(请参阅计划设置),也可以运行查询一次以将数据加载到Logstash。结果集中的每一行都变成一个事件。结果集中的列将转换为事件中的字段。”
jdbc_driver_library,必须!字符串类型,JDBC驱动程序库路径,多个库的话,可以通过逗号分隔它们。这个可以前往mysql官网下载,目前最新的版本是Connector/J 8.0.23,像我这种菜鸟就选择platform independent版本,rpm版本折腾不来,可以选择注册一个账号支持一下:
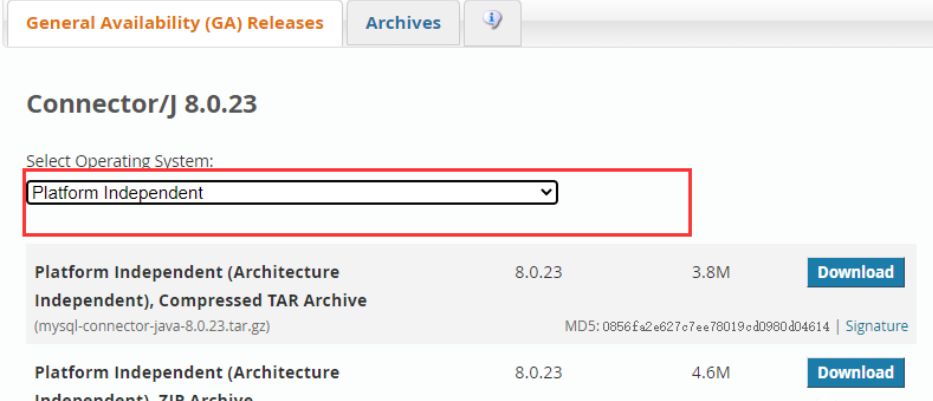
我下载到服务器的/usr/src/目录,解压之后,可以看到这个文件的路径就是待会我要指定的jdbc_driver_library参数:

jdbc_driver_class,必选!要加载的JDBC驱动程序类,字符串类型,我选择的是com.mysql.jdbc.Driver,在加载时可能会报一些错误,按照提示来做就可以。
jdbc_connection_string,必选!JDBC连接字符串。上述示例中我连接的是本地数据库的NBA数据库。
jdbc_paging_enabled,可选,默认为布尔型false,将一个sql语句分解为多个查询。每个查询将使用限制和偏移量来集体检索完整的结果集。限制大小是使用jdbc_page_size(默认10万条)限定的,需要注意的是无法保证查询之间的顺序。
tracking_column,可选,如果use_column_value设置为true,则要跟踪其值的列,上例中是在statement中定义的unix_ts_in_secs。
tracking_column_type,可选,二选一,["numeric", "timestamp"]。
schedule,可选,定期运行语句的时间表,默认情况下没有时间表。如果没有给出时间表,则该语句仅运行一次。
statement,可选,要使用参数,使用命名参数语法,如下例中的:target_id指代parameter中定义的值
# 如jdbc中定义的parameters
parameters => { "target_id" => "321" }
"SELECT * FROM MYTABLE WHERE id = :target_id"
上例中,有几个概念一起来捋一捋,一个是UNIX_TIMESTAMP,将返回一个时间戳(也就是UTC时间1970年01月01日00时00分00秒到现在秒数)。另外就是sql_last_value,这是一个内置参数,用于计算要查询的行的值, 在运行任何查询之前,它将设置为1970年1月1日,星期四;如果use_column_value为true并且设置了tracking_column,则将其设置为0,也就是说上面我设置了tracking_column,它将会被替换为tracking_column里面的值,这个值会默认保存在last_run_metadata_path中,如果没有设置这个参数,则默认路径为$HOME/.logstash_jdbc_last_run,按照上面的配置里面存放的就是一个时间戳。
SELECT 语句会取两个字段,一个是nba_test中所有字段,另外是定义的别名unix_ts_in_secs,而为什么里面的查询语句要这样写,可以参考官方文档(下方参阅第一篇)里面的解释,写的很清楚了。
需要注意的是,我的mysql表结构里面已经存在一个名为update_time的字段,并且设置了自动更新,如果发现自己的时间多出了小数点后几位数,可以检查下表结构里面的字段时间类型是否设置了长度,如果为0,则不存在小数点。

filter中,我主要是做了时区的处理,由于我们是东八区,所以从数据库里面同步到es的日期会减少8个小时,首先在ruby中,执行了一个代码code,因为我有两个时间需要转化,所以将其都放在了一个字符串里面(一定要注意,只接受字符串),让我们的字段内容Participation_date增加8个小时。
调用mutate复制数据库中的number去写到了[@metadata][_id],后面我们将会使用它将充当es中的id编号。convert转换字符串(因为下面使用的gsub只支持字符串),再使用gsub去掉多余的内容,得到正确的时间。更多信息可以在官网中的filter plugin中查看。
output中,输出到控制台排查问题,输出内容到es的索引和对应id。
logstash配置代码准备好了,就可以开始建es索引了,预先导入数据,或者直接开启logstash让它帮你同步都是可以的。
当你存在logstash_jdbc_last_run文件时,即使多次重启logstash,也不会插入数据到es(因为logstash会通过logstash_jdbc_last_run里面的最后更新时间戳来判断你的数据更新了没有),而当logstash_jdbc_last_run被删除掉之后,logstash启动第一件事就是全量同步数据,这一点可以从es的version中看到。利用这个特性,我们可以修改logstash_jdbc_last_run里面的值以控制其是否更新,例如,我的测试数据有200万条,加入logstash一开启就开始同步,那服务器估计得崩溃,所以可以先将数据全部导入至es中,然后修改logstash_jdbc_last_run里面的时间戳为你数据最后更新的时间(时间戳)这个时间戳千万别乱改,什么意思呢?例如,我的数据库里面最新一条数据更新时间为2021-04-17 15:06:25,那我把logstash_jdbc_last_run里面的时间戳修改成这个,然后再次启动logstash,可以发现,这条数据更新时间之前的全部不会再重复更新,而修改数据之后,照样可以正常更新。
发现一个es关于日期的巨坑,中国时区并不是+8个小时那么简单(准确的说是零时区的时间问题),经过我一条条测试,当你的mysql时间字段内容在1901-01-01这个日期之后,以该天为例,对应的是1900-12-31T16:00:00.000Z,但如果你稍微往前推一天,也就是数据库里面存放的时间为1900-12-31,那么你通过logstash取出来的时间会变为1900-12-30T15:54:17.000Z,也就是说相隔了5分43秒,目前还没有查到具体原因,去官方论坛提问了,对于这个解决方案我是采取下面的方式解决的,因为我对时间(时分秒)没有要求,只要正确的日期,所以时间只要没加到24个小时就还是当天的日期,效果对于我而言是一样的。
event.set(....time.localtime + 8*60*60 + 5*60+43)
关于logstash同步数据时,遇到相同id的处理方式:通过logstash同步时,ES中允许相同的主键存在,不会报错,但是根据version的不同,展示的始终会是最新的数据(version值最大)。
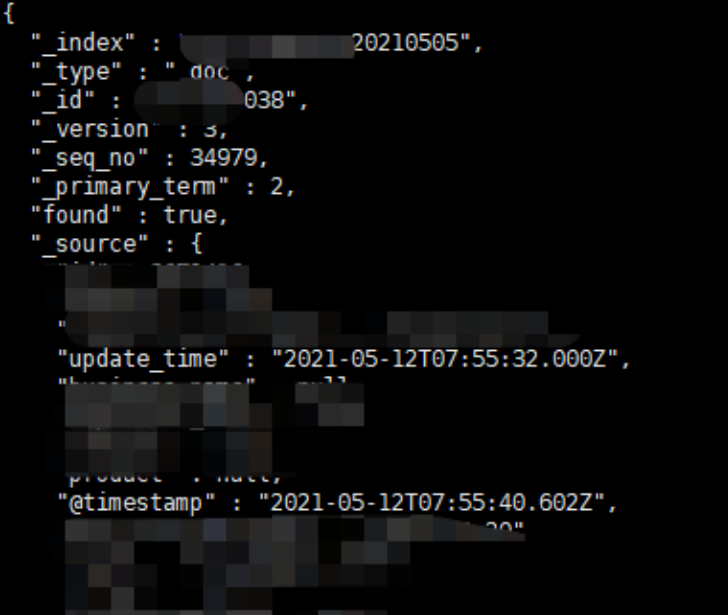
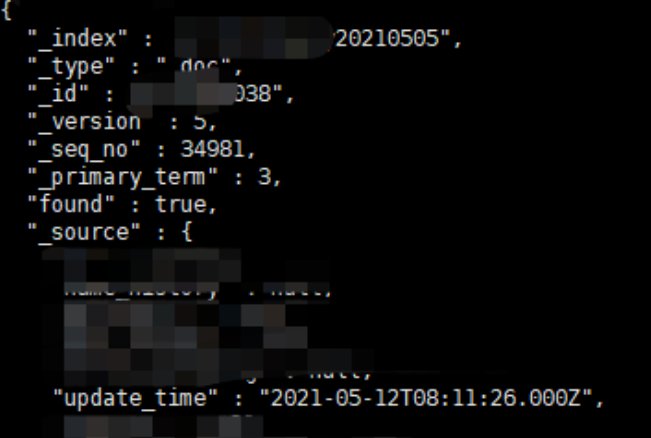
在logstash同步数据时,我做了两条主键(针对es中)一样的数据,两条数据先后导入到es中,在使用get方法查询内容时,可以发现始终取到的是version最大的那条数据,如上图两张。
参阅:
#官网logstash指导文章,简直就是引路人
https://www.elastic.co/cn/blog/how-to-keep-elasticsearch-synchronized-with-a-relational-database-using-logstash
# logstash指引
https://www.elastic.co/guide/en/logstash/current/getting-started-with-logstash.html
# 关于elasticsearch的format - failed to parse date field
https://github.com/elastic/elasticsearch/issues/43966
# ruby cody Expected string
https://discuss.elastic.co/t/need-some-help-with-ruby-split/189368/2
# 安装jdk9 - UseConcMarkSweepGC was deprecated in version 9.0
https://yanglinwei.blog.csdn.net/article/details/105146395
# Timestamp field has a 5 minutes delay
https://discuss.elastic.co/t/timestamp-field-has-a-5-minutes-delay/99679