最近有个需求,想要将各位球星的生日聚合起来,做一个日期分类页,以为很简单,毕竟在sql语句中group by可以解决,而在django模型中,通过queryset的api很轻松可以完成,而在es中,通过post请求,也是很简单就可以完成桶聚合,例如:
POST /nba/_search
{
"aggs": {
"aggsAge": {
"terms": {
"field": "birthDay",
"size": 2
}
}
},
"size": 1
}
这些我都已经做过测试,但是万万没想到,利用python通过elasticsearch-dsl来进行聚合的路会这么曲折。。。
一开始我是按照dsl官方的Aggregations文档来进行操作,例如:
s = Search()
a = A('terms', field='category')
s.aggs.bucket('category_terms', a)
response = my_client.execute(ignore_cache=True)
但是一直没有成功取到聚合的数据,打印出的response始终是普通数据,后来看到下面有一句释义
As opposed to other methods on the Search objects, defining aggregations is done in-place (does not return a copy).
“与Search对象上的其他方法相反,定义聚合是就地完成的(不返回副本)。”
我一直没有搞明白这句话的含义,但是在寻找答案的时候找到了两种解决方案。
第一种比较好理解一点,直接使用elasticsearch库,如下:
from elasticsearch import Elasticsearch
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
def addAggregationDate():
r = es.search(index='nba',
body={
"aggs": {
"aggsAge": {
"terms": {
"field": "birthDay",
"size": 5
}
}
},
"size": 1
})
print(r['aggregations']['aggsAge']['buckets'][0]['key_as_string'])
这种跟寻常操作一样,索引index并非必须指定,但如果不加入,会被提示“将来的主要版本中。默认情况下将禁止直接访问系统索引”,因为使用的是es 7.*,所以doc_type只有一种,不指定也没问题,在body中定义了聚合名称为aggsAge。这个r返回一个字典,如下
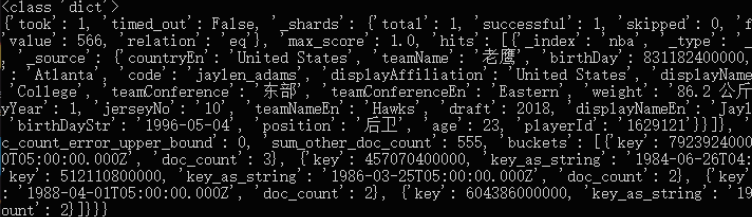
最后利用字典的特性取出想要的日期。
第二种,通过elasticsearch_dsl封装库,代码如下:
client = Elasticsearch()
my_client = Search(using=client, index="nba")
def addAggregationDate():
# a= A('terms',field="birthDay",size=2)
# my_client.aggs.bucket('myaggs', a)
my_client.aggs.bucket('myaggs', 'terms',field="birthDay",size=10)
res = my_client.execute()
for term in res.aggregations.myaggs.buckets:
print(term.to_dict())
print(term.key_as_string)
forma = time.strptime(term.key_as_string,'%Y-%m-%dT%H:%M:%S.%fZ')
reallytime = time.strftime("%Y-%m-%d", forma)
注释的那两行写法和my_client.aggs.bucket的作用一样的,我在bucket定义了一个名为myaggs的聚合,res.aggregations是一个AggResponse对象(继承至AttrDict),所以当打印res.aggregations内容时发现展现不全,可以使用to_dict()函数打印完整内容,for循环中term是一个elasticsearch_dsl.response.aggs.FieldBucket对象,其实本质上也是AttrDict的子类,term.to_dict()和term区别如下:

由于es中的数据是通过logstash同步过来的,所以term.key_as_string取出来的值是一个类似于1995-02-10T05:00:00.000Z的字符串,这种肯定不是我想要的格式,在下面我通过strptime函数将字符串解析成一个时间元组,
time.struct_time(tm_year=1995, tm_mon=2, tm_mday=10, tm_hour=5, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=41, tm_isdst=-1)
再通过strftime函数将获取到的时间元组以我设定的格式输出,最终变成了1995-02-10这种标准格式。
参考:
#elasticsearch python queries - Group by field and then count
https://stackoverflow.com/questions/52381621/elasticsearch-python-queries-group-by-field-and-then-count
#python中时间日期格式化符号
https://blog.csdn.net/lin49940/article/details/86653286
# How to get aggs in elasticsearch-dsl-py
https://stackoverflow.com/questions/34403211/how-to-get-aggs-in-elasticsearch-dsl-py