pandas中对于时间的解析使用to_datetime函数,非常智能
pd.to_datetime('20210804')
pd.to_datetime('04/08/2021')
>Timestamp('2021-04-08 00:00:00')
当我们传入一个列表时,转化出来的就会是一个DatetimeIndex时间索引
pd.to_datetime(['04/08/2021'])
>DatetimeIndex(['2021-04-08'], dtype='datetime64[ns]', freq=None)
我们可以使用date_range函数生成一个固定频率的DatetimeIndex,看下官方介绍
Signature:
pd.date_range(
start=None,
end=None,
periods=None,
freq=None,
tz=None,
normalize=False,
name=None,
closed=None,
**kwargs,
)pd.date_range(start='20210601',periods=200,freq='5H')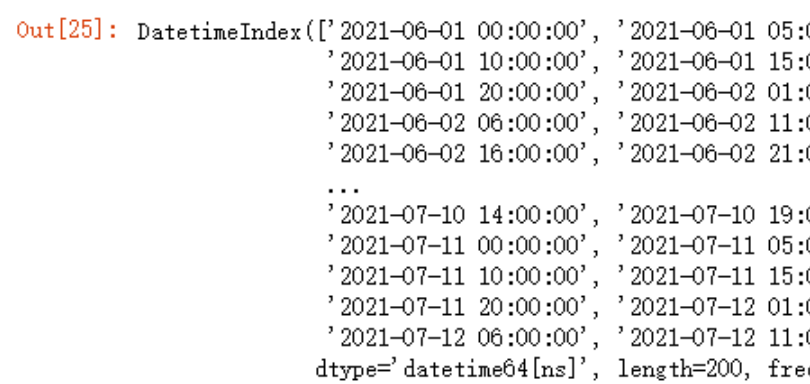
当我们的数据存在时间索引时,我们就可以定义它为时间序列
data = pd.Series(np.random.randn(100),
index=pd.date_range(end='20210804',
periods=100))
data
取时间序列非常方便,可以用具体的时间取值,也可以切片取值
data['2021-05-01']
data['20210501':'20210511']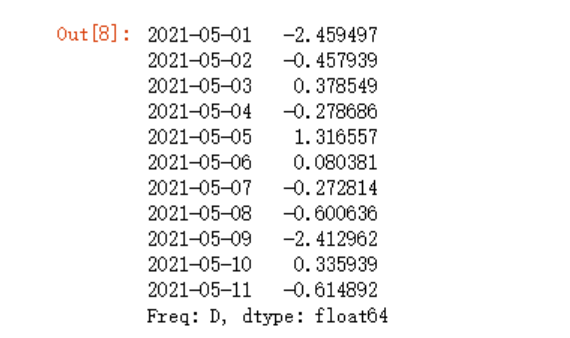
pandas甚至可以了解我们想要用月份来切片,例如
data['2021-05':'2021-06']
时间序列中的运算会根据对齐的时间索引来进行运算,而未对齐的值会返回一个NA,测试如下
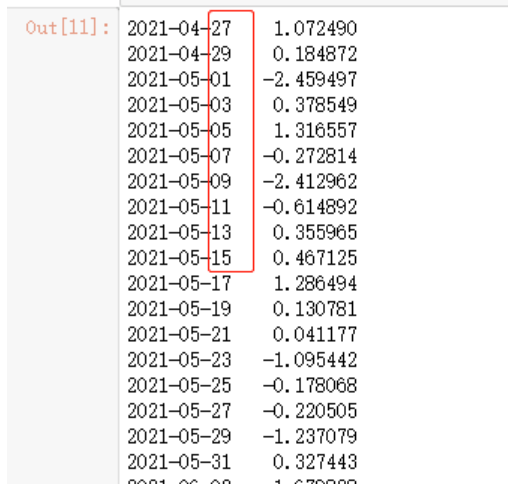
data_test = data[::2]
data_test
data_test + data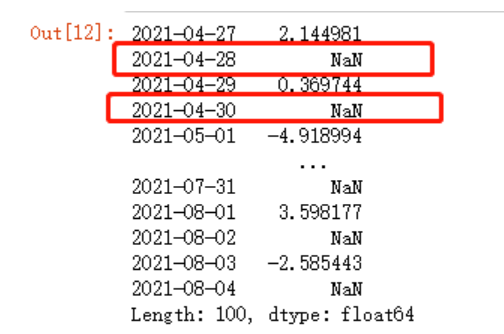
时间序列重采样
照例,来看下官网对重采样resample的定义以及参数。
定义:Resample time-series data,重新采样时间序列数据。从一个频率到另一个频率:降采样,升采样,采样时间点变化。降采样就是比如之前是每天的频率到每月的频率,升采样例如每月的频率到每天,采样时间点变化例如之前是每周五采样,现在需要改成每周三。
Signature:
data.resample(
rule,
axis=0,
closed: 'str | None' = None,
label: 'str | None' = None,
convention: 'str' = 'start',
kind: 'str | None' = None,
loffset=None,
base: 'int | None' = None,
on=None,
level=None,
origin: 'str | TimestampConvertibleTypes' = 'start_day',
offset: 'TimedeltaConvertibleTypes | None' = None,
) -> 'Resampler'
Docstring:
Resample time-series data.
还是上面的例子:
data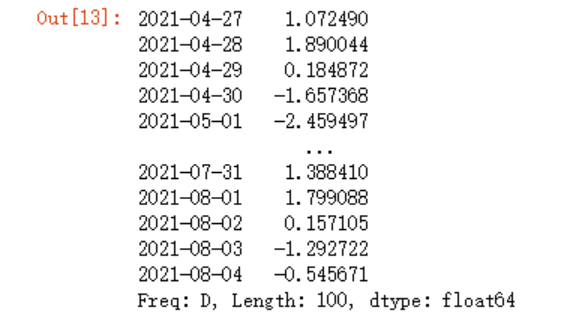
现在我想要对其进行降采样,由每天的频率变成每月的频率,并取平均值
data.resample(rule='M').mean()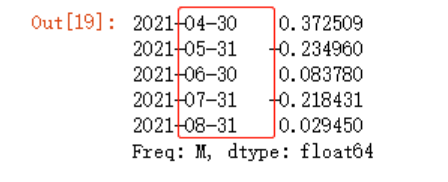
可能你会看到这data数据明明只生成到了2021年8月4号,为何在下面重采样的数据显示到了2021年8月31号,这只是展示形式,实际上算的平均数还是8月1号到8月4号(我已经核算了一遍)。
例如,现在有一份文件如下:
df.head()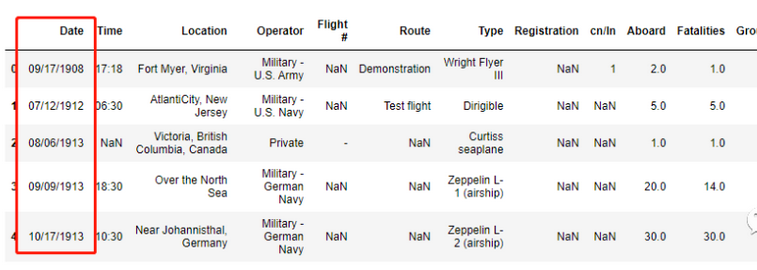
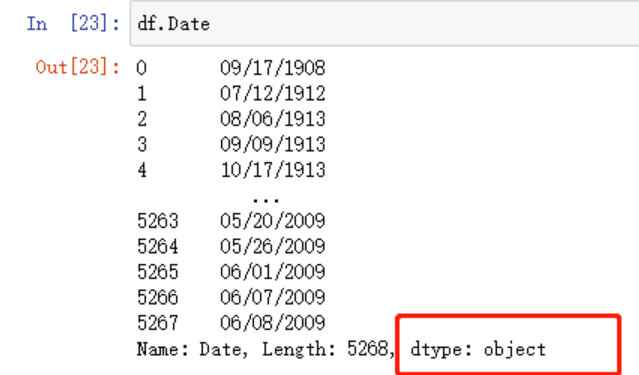
这里面读取的日期默认是一个普通列对象,现在我想把这份数据变为时间序列,那么首先应该将日期这一列指定为索引!pandas怎么读取csv文件?
df = pd.read_csv('./air1908.csv', index_col='Date')
df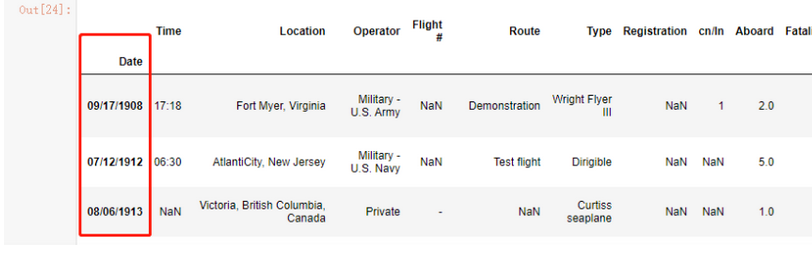
后面的参数还应该增加一个parse_dates参数
df = pd.read_csv('./air1908.csv',
index_col=['Date'],
parse_dates=True)
df
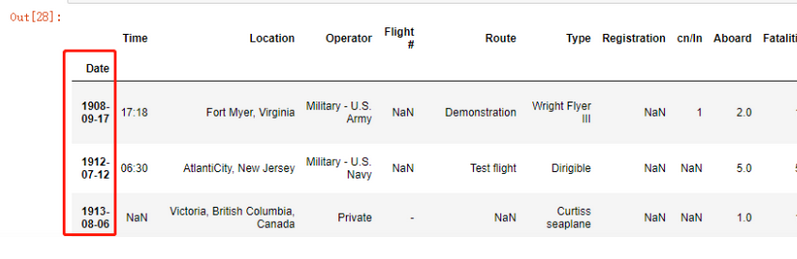
此时df.index返回的是一个DatetimeIndex。
此时我们想计算出每年的着陆人数就很好计算了
df['Ground'].resample('A').sum()
股票分析实例
股票数据来源于开源库tushare,选定的股票代码为洁柔002511,刚好笔者有个表弟最近沉迷于洁柔股票,正好拿来当实例学习下。
import tushare as ts
jr = ts.get_k_data('002511', autype='hfq', ktype='D', start='2018-12-17', end='2021-08-04')
jr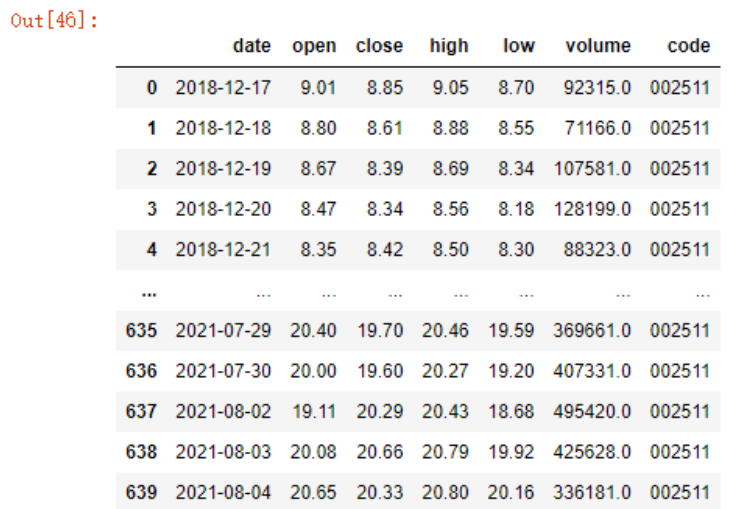
首先将日期一列转为索引,我们来看下目前的索引和列名
jr.columns
jr.index
转换索引,我们可以采用两种方法,一种是直接命名法,这种直接就在源数据上修改了
jr.index=jr.date
另外一种是使用set_index函数,生成一个新的副本,关于set_index函数介绍如下:
Set the DataFrame index using existing columns.Signature:
jr.set_index(
keys,
drop: 'bool' = True,
append: 'bool' = False,
inplace: 'bool' = False,
verify_integrity: 'bool' = False,
)
Docstring:
Set the DataFrame index using existing columns.
jr.set_index('date')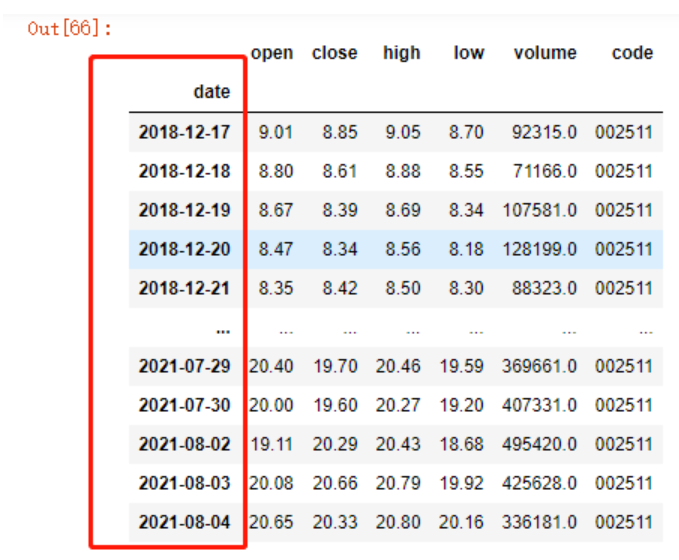
此时,可以看到,date一列已经作为了索引,看着挺像时间索引,但是绝对不是,我们可以打印出来看下
jr.index
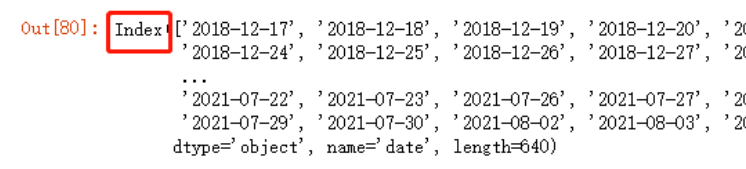
也就是说我们还需要把这一列转换为时间索引,这里可以使用to_datetime函数,本文的第一部分介绍过,可以试一下
pd.to_datetime(jr.index)
jr.index = pd.to_datetime(jr.index)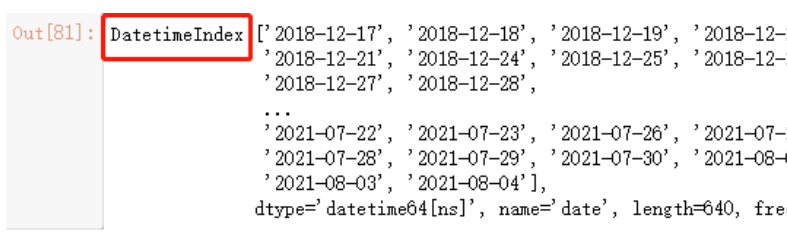
此时再按照切片语法取值就很方便了
jr["2019":"2020"]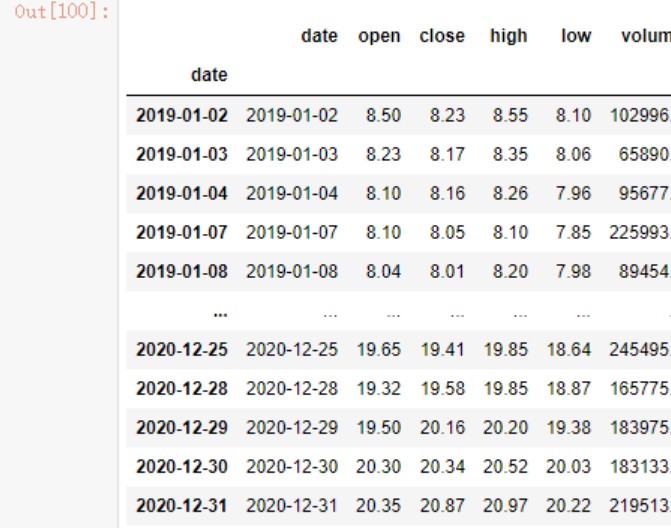
假如我现在想要看下它的这几年收盘价,嗯,看着还行
jr.close.plot(figsize=(10,8))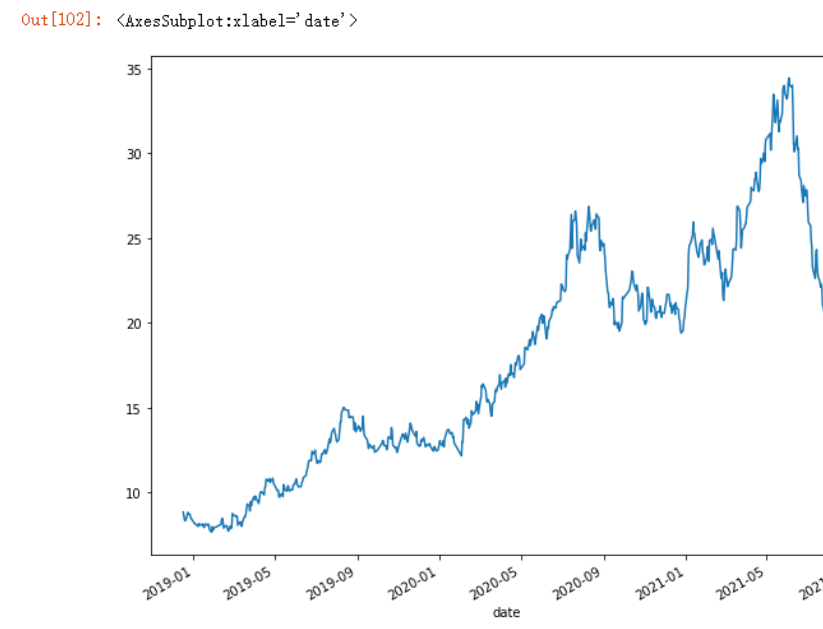
利用采样看下每一年收盘价的平均值,可以看到我并没有使用groupby等函数聚合年份,仅仅是传入了一个A参数,数据就自动聚合了
jr.close.resample('A').mean()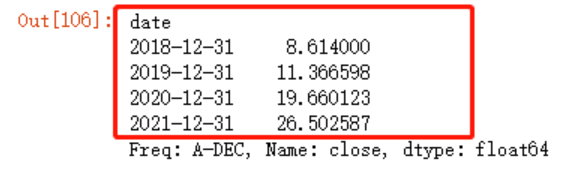
单独的选取年份,也很方便
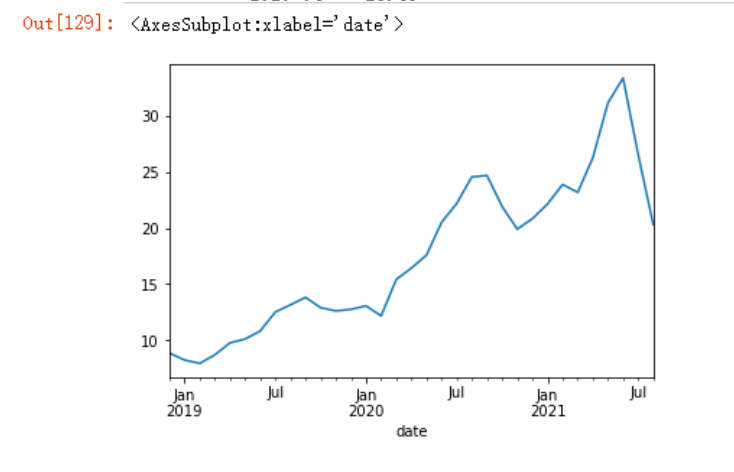
jr.loc['2021'].close.plot(figsize=(14,8))
# 或者直接利用时间序列
# jr.close本身就是一个时间索引
jr.close['2021'].plot(figsize=(14,8))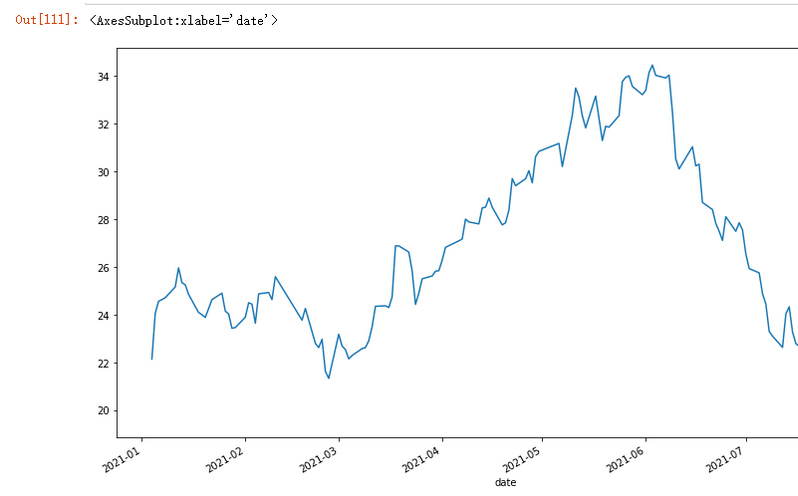
如果计算第一天买入,到今天抛出,赚取的利润
(jr.close[-1]-jr.close[0])/jr.close[0]
>1.2971751412429378
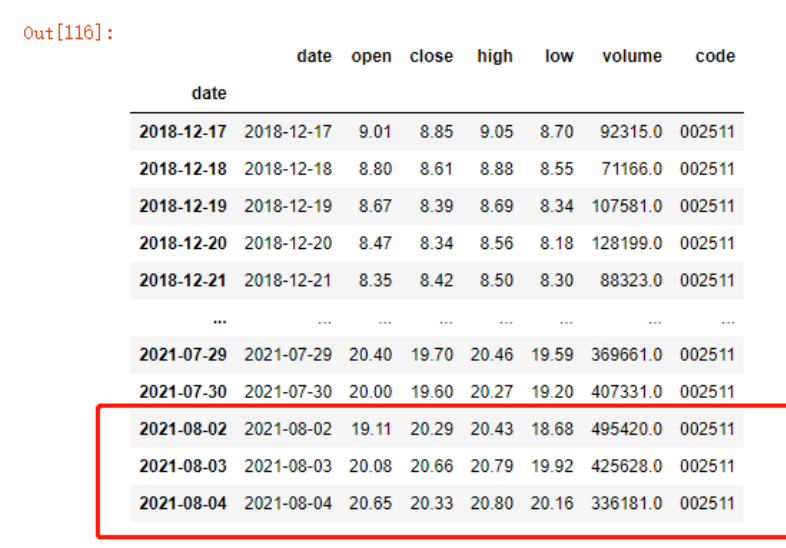
我们也可以利用to_period函数将Series从DatetimeIndex 转换为 PeriodIndex。先来看下原始数据
jr
jr.close.to_period('M')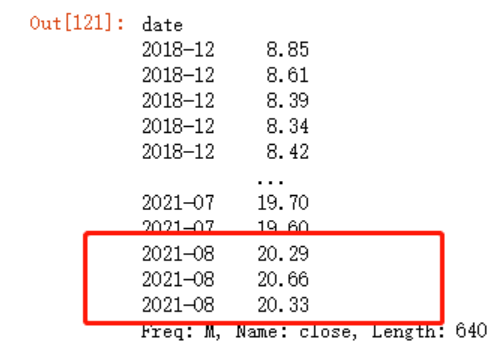
可以看到,数据的内容本身不会有任何改变,只是将时间索引作了修改,方便聚合。现在我想得到每个月初的收盘价,
jr.close.to_period('M').groupby(level=0).first()
#等价于
jr.close.to_period('M').groupby('date').first()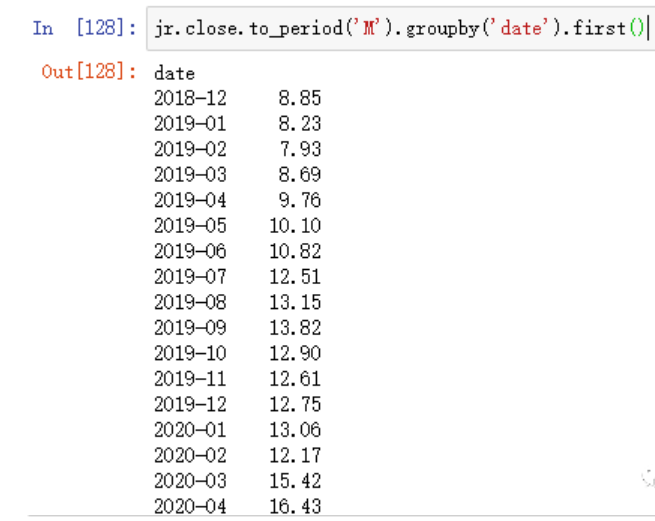
比如想要算出股票的波动率,首先需要知道对数收益率:所有价格取对数后两两之间的差值。
(log(30) - log(20) = log(30/20))
log(a) - log(b) = log(a/b)jr.close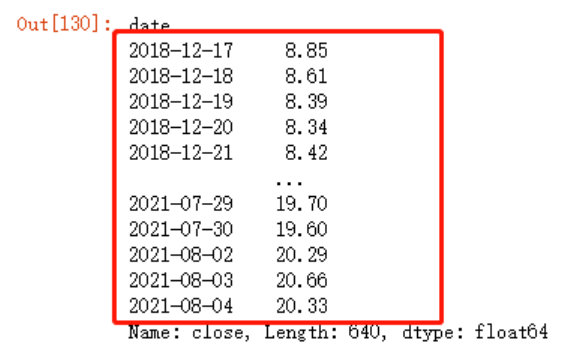
往后推移一位
jr.close.shift(1)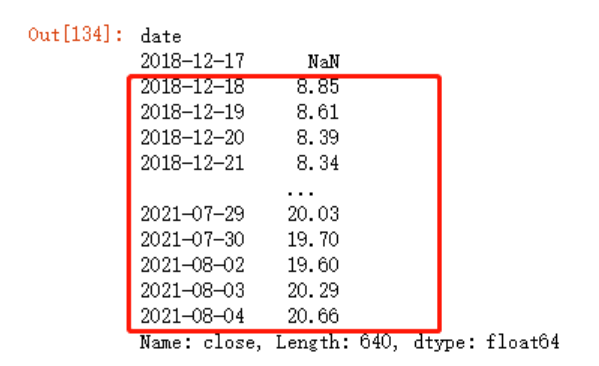
jr['ds']=np.log(jr.close/jr.close.shift(1))
jr
绘图如下
jr[['close','ds']].plot(subplots=True, figsize=(14,8))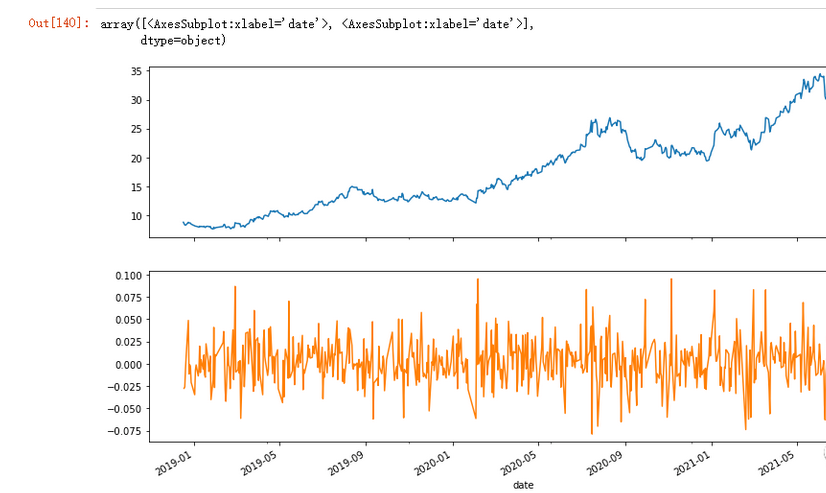
参考
https://zhuanlan.zhihu.com/p/35943334