准备工作:
两台服务器,服务器的版本分别如下
Linux VM-20-14-centos 4.18.0-305.10.2.el8_4.x86_64 #1 SMP Tue Jul 20 17:25:16 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Linux Paris 4.18.0-240.1.1.el8_3.x86_64 #1 SMP Thu Nov 19 17:20:08 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
elasticsearch 7.10.0版本(两台服务器上分别下载,解压)
1.服务器上配置文件的修改,修改文件限制:
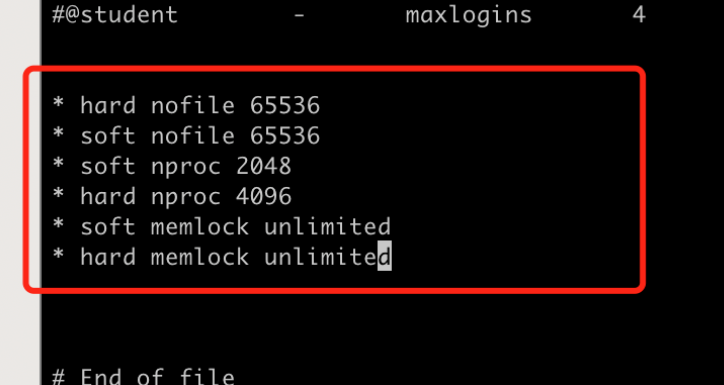
vi /etc/security/limits.conf
* hard nofile 65536
* soft nofile 65536
* soft nproc 2048
* hard nproc 4096
* soft memlock unlimited
* hard memlock unlimited
2.调整进程数,首先运行如下命令,查看最大线程数
ulimit -u

vi /etc/security/limits.d/20-nproc.conf
* soft nproc 4096
root soft nproc unlimited
再次重新登录服务器

3.调整虚拟内存&最大并发连接(实测,前面两点不设置没有关系,但是这个max_map_count必须配置,否则es启动会报错)
vi /etc/sysctl.conf
vm.max_map_count=655360
fs.file-max=655360
#立即生效
sysctl -p
4.创建用户(elasticsearch规定不能以root用户启动)
useradd es
# 查看添加的用户
tail /etc/passwd
可以看到最后一行确实添加了一个名为es的用户,为解压出来的elasticsearch目录赋予权限,赋权之前

赋权之后(chown的含义为change owner):
chown -R es:es elasticsearch-7.10.0

这个时候我们切换到es身份就可以启动elasticsearch了
su es
./bin/elasticsearch
先以前台启动的方式看下,这里插句题外话,因为笔者有台服务器的配置仅为1G内存(free -m查看可用内存),所以刚开始一运行就显示killed,这时候可以修改config目录下的jvm.options文件的堆内存大小,建议二者配置成一样
-Xms128m
-Xmx128m

为什么没有解释JAVA环境,是因为目前我使用的elasticsearch内置了JDK,所以无需单独配置。
为了方便监测elasticsearch的状态,有两个合适的可视化插件,分别是elasticsearch-head和cerebro。
先说head插件,由于安装head需要node环境,干脆安装了一个node虚拟环境NVM。
curl https://raw.githubusercontent.com/creationix/nvm/master/install.sh | bash
source ~/.bashrc
这个时候ls ~ -al就可以看见HOME目录下面有一个名为.nvm的隐藏目录了,可以用如下代码查看有哪些版本的NVM可以提供安装,选择其一即可
nvm ls-remote
nvm install v14.18.1
nvm ls
可以开始按照官方文档安装head插件了,官网链接在下方参考中
wget https://github.com/mobz/elasticsearch-head/archive/refs/heads/master.zip
unzip master.zip
cd elasticsearch-head-master/
npm install
npm run start
如果在安装phantomjs时报了错,如下,
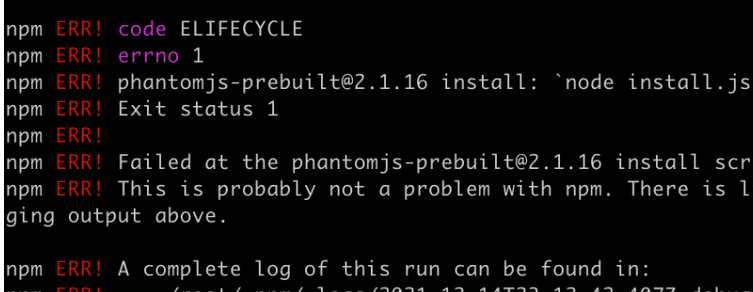
可以采取如下代码来进行安装:
npm install phantomjs-prebuilt@2.1.16 --ignore-scripts
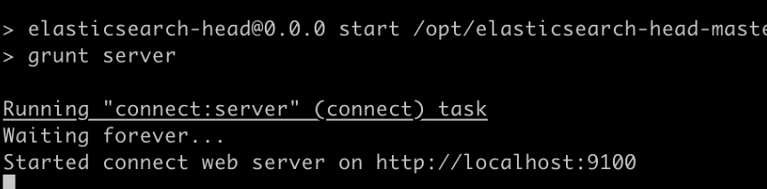
如果此时访问本地9100端口,没有提示Connection refused那么就说明已经成功启动了。
但是对于我来说,肯定希望能通过公网来访问,安装grunt
npm install -g grunt-cli
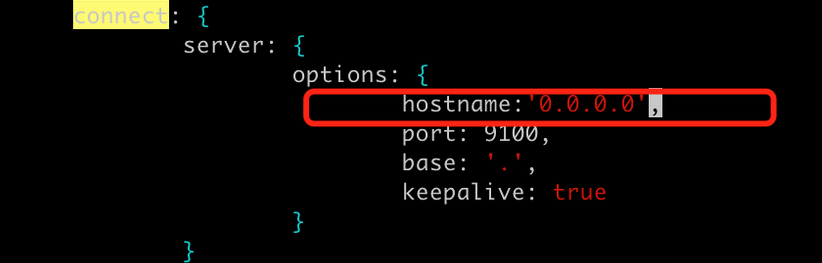
我已经在防火墙放行9100端口并重启防火墙生效,修改head目录下的Gruntfile.js文件,添加如下代码:
hostname:'0.0.0.0'
_site/目录下面的app.js

如果是国内主机,还一定要在云服务器的主机管理界面打开防火墙哦!这样就可以通过外网访问head插件了
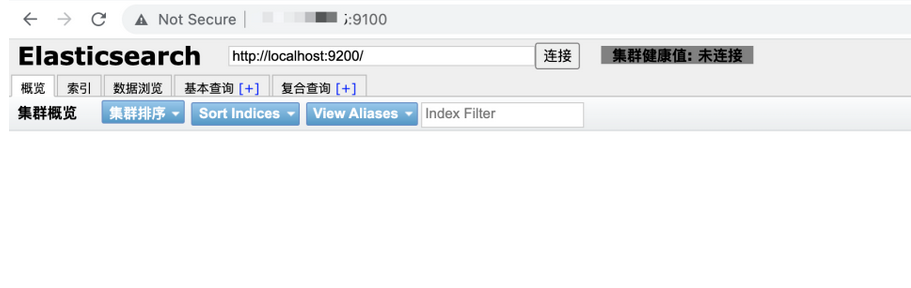
集群未连接,是因为还需要去配置elasticsearch的配置文件,找到elasticsearch.yml配置文件,添加如下内容:
http.cors.enabled: true
http.cors.allow-origin: "*"
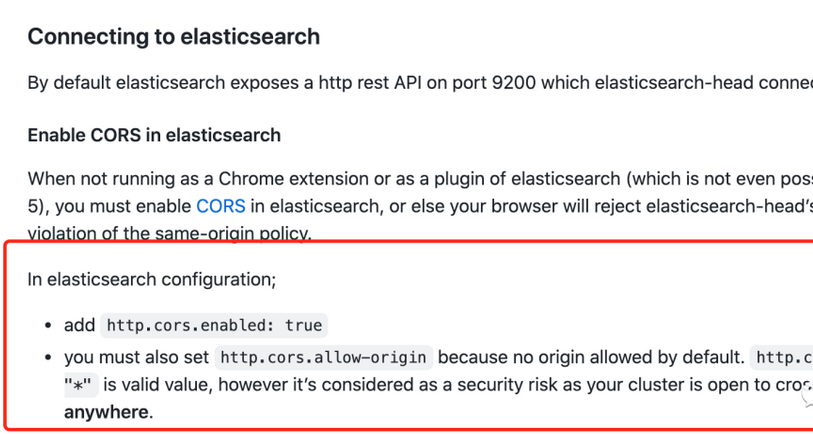
重新启动es。
./bin/elasticsearch -d
再次访问9100端口,可以看见集群已经链接
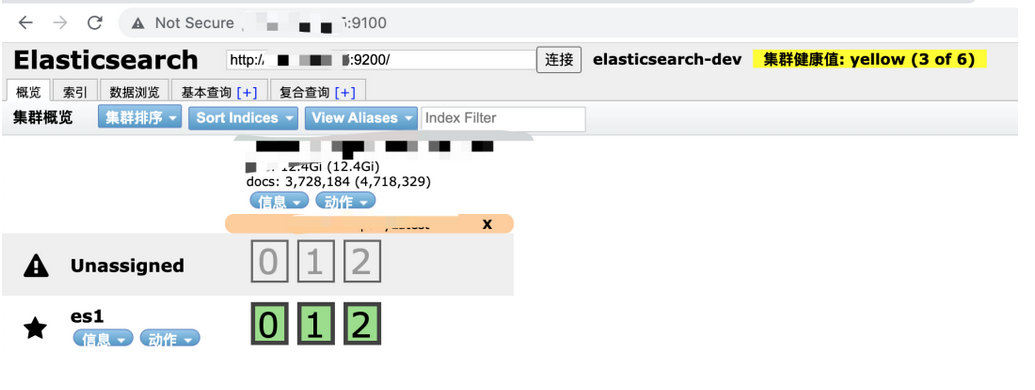
因为我一开始做测试的时候设置了分片为三主一副,而现在又只有一个节点,所以副本分片无处安放导致集群健康值为黄色,当然也可以在这台服务器上再新建一个elasticsearch节点(更换端口),但没必要,毕竟多节点是为了预防故障的,还是水平扩展比较好。
开始配置另一外服务器的elasticsearch,一定要注意,两个elasticsearch软件之间的数据应该是一样的,即data目录下面保持相同,否则单节点启动没有问题,但是双节点一加入就会报错!
服务器之间通过防火墙放开指定公网IP的9300端口用于es内部通讯,主服务器elasticsearch.yml文件内容如下(ps:网上的好多教程真坑,都是在内网测试的教程,公网集群测试着实是少,注意下面的network.bind_host和network.publish_host两个配置!):
cluster.name: elasticsearch-dev
node.name: es1
path.data: /opt/elasticsearch-7.10.0/data
path.logs: /opt/elasticsearch-7.10.0/logs
node.master: true
node.data: true
network.bind_host: 10.0.20.14 #设置绑定的ip地址,这里使用内网ip
network.publish_host: 1****5 #设置其它节点和该节点交互的ip地址,把他设置为外网IP
transport.tcp.port: 9300
http.port: 9200
discovery.seed_hosts: ["1*****5:9300", "1******3:9300"]
cluster.initial_master_nodes: ["es1","es2"]
http.cors.enabled: true
http.cors.allow-origin: "*"
副节点配置如下:
cluster.name: elasticsearch-dev
node.name: es2
path.data: /opt/elasticsearch-7.10.0/data
path.logs: /opt/elasticsearch-7.10.0/logs
node.master: false
node.data: true
network.bind_host: 10.0.20.14 #设置绑定的ip地址,这里使用内网ip
network.publish_host: 1*****3 #设置其它节点和该节点交互的ip地址,把他设置为外网IP
transport.tcp.port: 9300
http.port: 9200
discovery.seed_hosts: ["1*****5:9300", "1******3:9300"]
cluster.initial_master_nodes: ["es1","es2"]
http.cors.enabled: true
http.cors.allow-origin: "*"
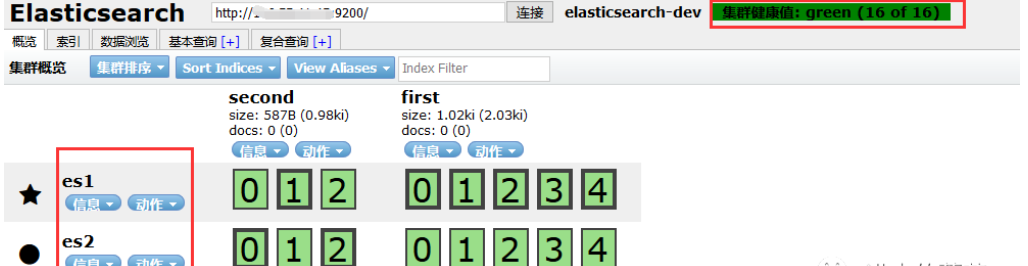
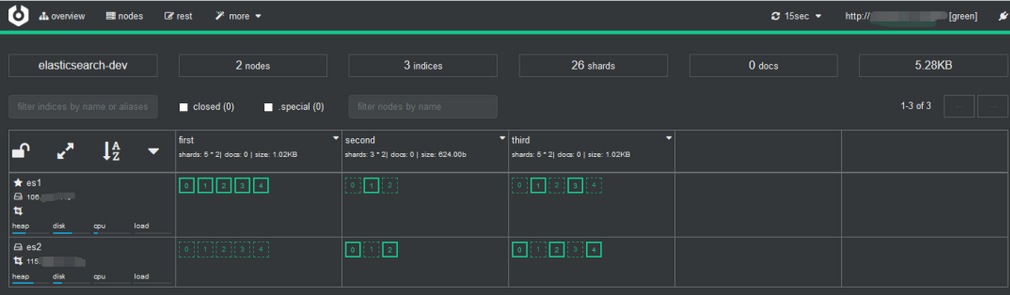
再次访问公网9100端口,主/副分片都正常分布到两个节点上,集群显示为为green
做事就要一步到位,完全开放不安全,对指定IP开放9100端口又着实有点麻烦,所以最好是增加一个权限认证才能进入这个界面,参考之前写过的文章- 关于http网站包装ssl和https网站日志可视化 和 利用GoAccess实现nginx日志可视化。
配置nginx.conf文件,在server段增加如下配置(因为head插件也是渲染其目录下的index.html文件)
location /head {
auth_basic "zhang";
auth_basic_user_file /usr/local/nginx/pwd/htpasswd;
alias /opt/elasticsearch-head-master/;
}
在服务器上关闭掉9100端口的访问
firewall-cmd --permanent --remove-rich-rule="rule family='ipv4' source address=ip port port=9100 protocol=tcp accept "
firewall-cmd --reload
那么此时就无法再通过9100端口访问head插件了,我们必须通过路径来访问
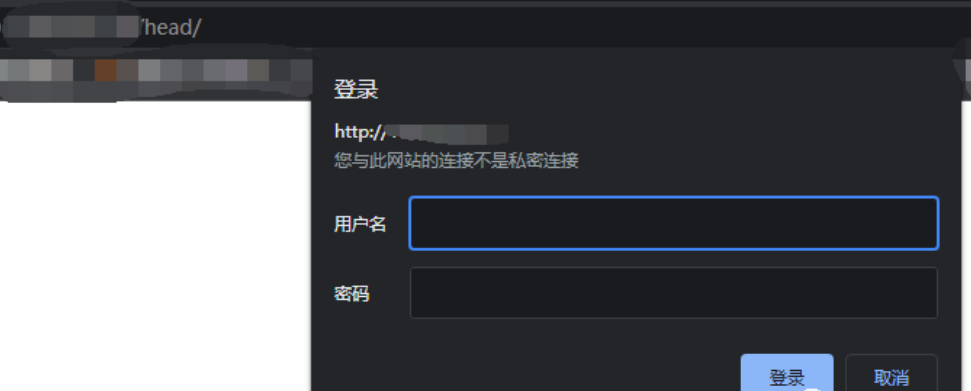
成功增加权限访问机制
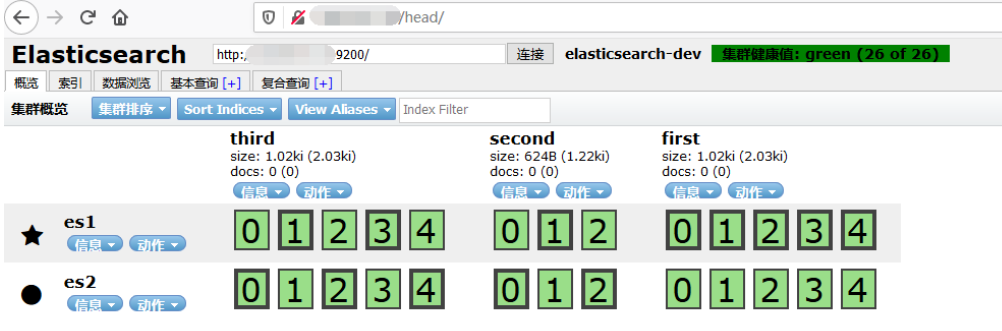
如果想要后台运行head插件,挂起即可
nohup npm run start &
按照官网链接(下方参考)安装cerebro插件。
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.tgz
tar -zxvf cerebro-0.9.4.tgz
因为该插件也是依赖于java,所以需要安装jdk,我尝试安装了Java SE Development Kit 17.0.1,但是无法启动cerebro,于是注册了一个oracle账号下载了Java SE Development Kit 8u311版本,成功启动。
tar -zxvf jdk-8u311-linux-x64.tar.gz
启动,指定java目录
./bin/cerebro -java-home /opt/jdk1.8.0_311
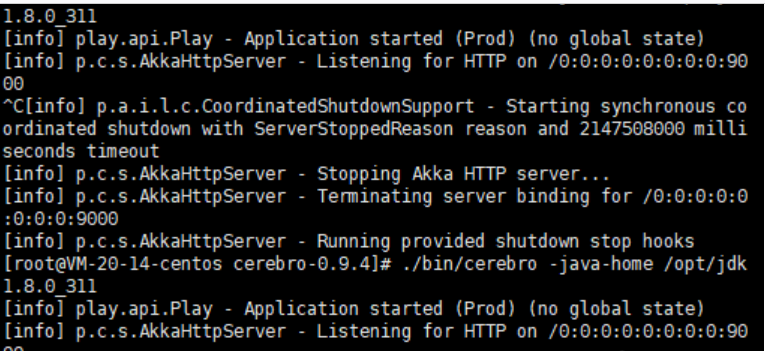
此时,访问本地9000端口不再被拒绝了
curl -XGET localhost:9000
防火墙放行9000端口后,访问公网ip:9000如下
我们输入http://ip:9200即可正常访问集群
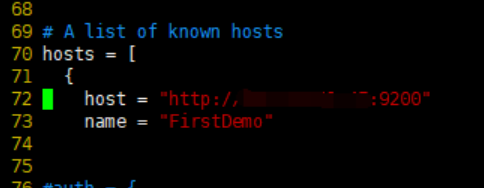
cerebro可以通过修改配置文件application.conf来解决重复输入节点路径的问题
vim conf/application.conf
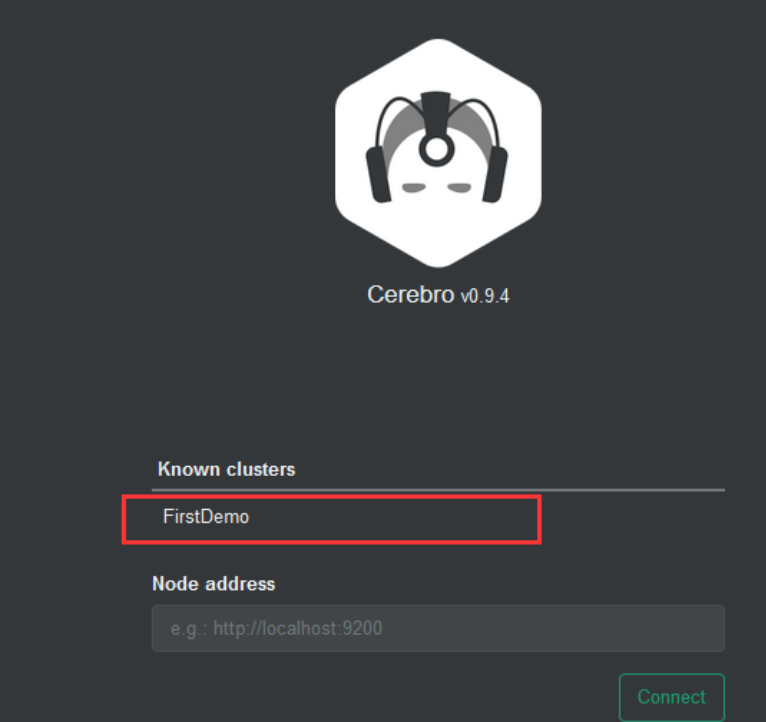
再次访问9000端口如下所示,直接点击名称即可访问集群状态
参考:#elasticsearch官网
https://www.elastic.co/cn/elastic-stack/
# 关于es和平台支持的对照表
https://www.elastic.co/cn/support/matrix
# java要求
https://www.elastic.co/guide/en/elasticsearch/reference/current/setup.html
# limits.conf详解
https://www.cnblogs.com/dongzhilong/p/5185248.html
# Installing NVM on CentOS 7
https://tecadmin.net/how-to-install-nvm-on-centos-7/
# elasticsearch-head
https://github.com/mobz/elasticsearch-head#running-with-built-in-server
# cerebro
https://github.com/lmenezes/cerebro
#network.bind_host
https://blog.csdn.net/weixin_43300503/article/details/88666968
# jdk
https://www.oracle.com/java/technologies/downloads/#java8