入门pandas,要熟悉两个常用的工具数据结构:Series和DataFrame。
Series是一维的数组型对象,包含了一个值序列,并且包含了数据标签,称为索引(index),最简单的序列可以仅由一个数组构成:
obj = pd.Series([4,5,7])
obj
> 0 4
1 5
2 7
dtype: int64
由于我没有指定索引,所以默认生成的索引为0到N-1,我们可以通过以下属性分别获取Series对象的值和索引:
obj.values
>array([4, 5, 7], dtype=int64)
obj.index
>RangeIndex(start=0, stop=3, step=1)
如果想要自定义索引,那么就需要创建一个索引序列,用标签标识每个数据点
obj2 = pd.Series([4,5,7],index=list('abc'))
obj2
> a 4
b 5
c 7
dtype: int64
上面的方法是在构造函数中初始化了索引标签,我们也可以通过位置赋值的方法动态的赋值索引:
obj.index = list('zxf')#['z','x','f']
obj
> z 4
x 5
f 7
dtype: int64
我们可以根据标签来索引数据
obj2['b']
>5
# 取多值
obj2[['a','b']]
也可以使用Numpy风格的操作,例如使用bool进行过滤,示例如下:
obj2[obj2>5]
> c 7
如果从另外一个角度来考虑Series,可以把它认为是一个长度固定且有序的字典,因为它将索引和数据一一对应,也就是说,我们可以将字典转化成Series:
data = {'a':111,'b':222,'c':333}
obj3 = pd.Series(data)
obj3
> a 111
b 222
c 333
dtype: int64
也许你会觉得这种排序方式不是你想要的,我们也可以将自定义排序传入到Series的构造函数当中
states = ['x','b','a']
obj4 = pd.Series(data, index=states)
obj4
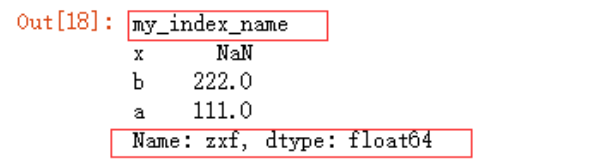
> x NaN
b 222.0
a 111.0
dtype: float64
上例中,因为x对应的没有值,所以显示的是Not a Number,而因为自定义的排序中没有c,所以它被排除在外。
我们可以使用isnull和notnull来检查缺失的数据(实例方法或者顶级方法都可以):
pd.isnull(obj4)
> x True
a False
b False
dtype: bool
Series还有自动对齐索引的特性,假如存在两个相同索引的Series,pd会尝试将其相加,如果无法得出数值,则会显示为NAN,示例:
obj3+obj4
> a 222.0
b 444.0
c NaN
x NaN
dtype: float64
上面的a索引对应值为111+111变成了222,而两个Series中不是共同拥有的索引则变成了NaN。
Series对象和其索引都有name属性,
obj4.name="zxf"
obj4.index.name="my_index_name"
obj4
如果需要计算,使用Series的实例方法即可,例如:
obj.mean()
obj.sum()
我们在计算时无须考虑缺失值,因为pandas会自动帮我们忽略掉。