DataFrame表示矩阵的数据表,它包含已排序的列集合,可以简单的把它理解成多列的Series,每一列可以是不同的值类型,在DataFrame中,存在行索引和列索引,它可以被视为一个共享相同索引的Series的字典,数据被存储为一个以上的二维块,而不是列表、字典或其他一维数组的集合。
《Python for Data Analysis》
构建DataFrame最常用的方式是利用包含等长度列表或Numpy数组的字典来形成DataFrame(以下简称为DF):
data = {'z':['one','two','three','four'],
'x':[111,222,333,444],
'f':666}
df1 = pd.DataFrame(data)
df1
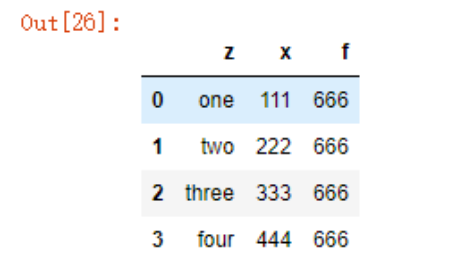
可以看到,生成的DF会自动为Series分配索引,列会按照顺序排列,我们也可以指定列的顺序:
df1 = pd.DataFrame(data, columns=list('xfz'))
df1

如果在传入的列值索引不被包含在字典中,则结果会出现缺失值,在此不做演示。
如果是嵌套字段被赋值给DF,pandas会将字典的键作为列索引,而内部字典的键作为行索引。
我们可以在DF中按照字典的属性检索为Series,以下提供两种方式,但需要注意,如果采用第二种方式,则要求columns中的值必须为符合python规范的变量名(备注,这些选取的列均为源数据的视图或者说是引用,而非拷贝,也就是说对Series的修改会映射到DF中,如果需要复制,必须显式的使用copy方法):
df1['z']
df1.z
# 取多值的方法类似Series

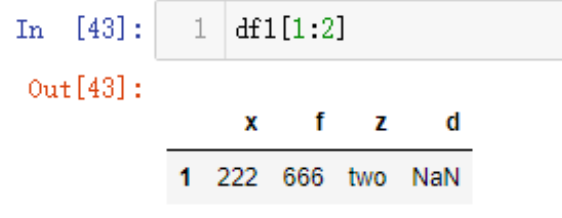
如果想要选取行数,可以采用位置或者特殊属性loc(轴标签)、iloc(整数标签)来选取。
位置行数很好理解,但有一个坑需要注意,例如我选择第二行,不能使用df[1],而必须切片
df1[1:2]
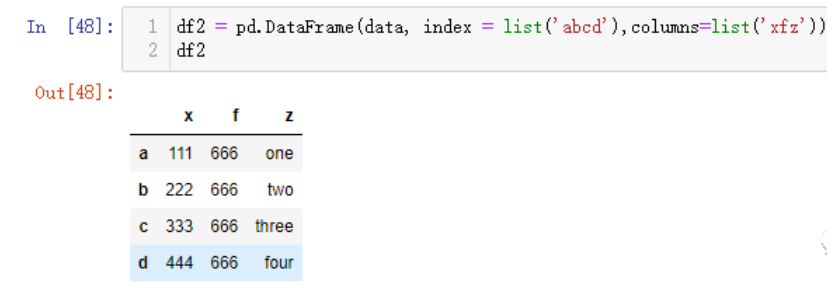
loc属性,前提是你已经定义了index行索引,注意是用['index']中括号来取值(增加行,也可使用该属性来操作)
df2 = pd.DataFrame(data, index = list('abcd'),columns=list('xfz'))
df2
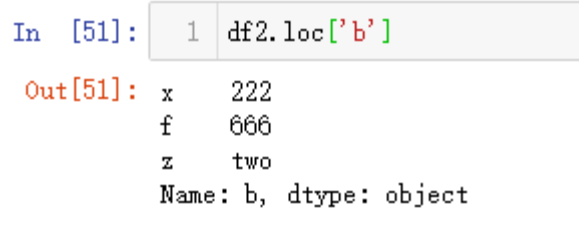
df2.loc['b']
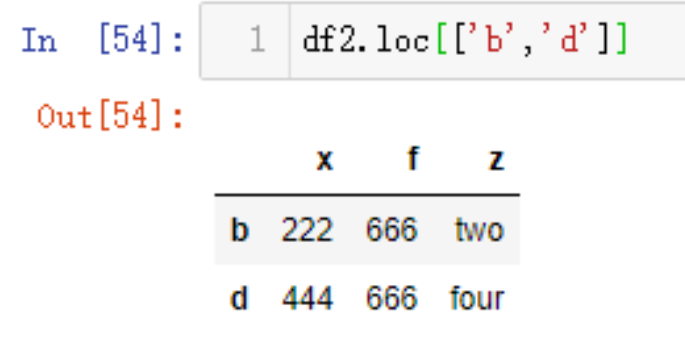
如果想要取多行数据,按需填入索引名称即可
df2.loc[['b','d']]
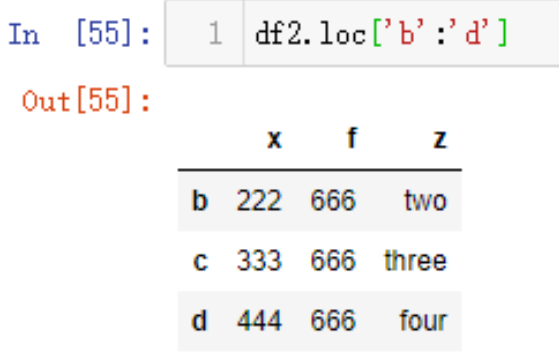
甚至我们可以采用切片语法来选取b和d之间的数据,与python切片不同的是这个取值是前包括,后也包括(注意:下面介绍的iloc又是符合python切片语法的)
df2.loc['b':'d']
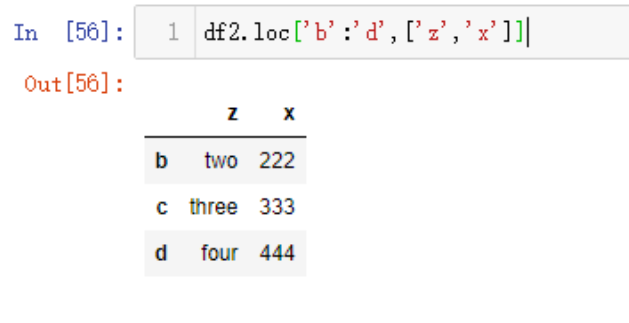
如果想要在选取行的基础上再筛选列,并把列排个序,也非常简单,以下的代码中我只想要z和x列,所以将其放入到一个新列表当中,而如果想要z和
x列之间所有数据,那么使用df2.loc['b':'d','f':'z']选定就可以了
df2.loc['b':'d',['z','x']]
iloc属性,可以直接传入某一行的位置获取数据
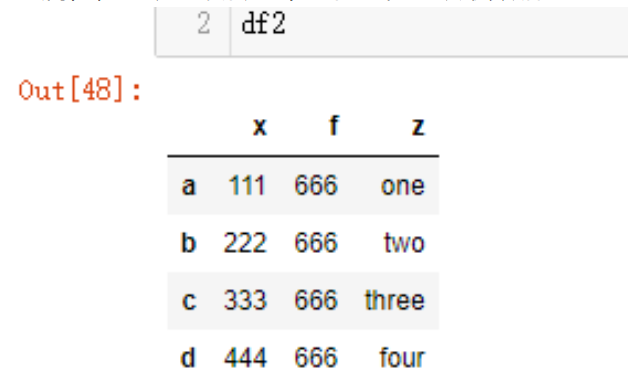
df2.iloc[2]
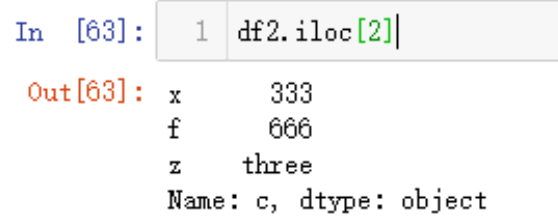
传入切片获取某行,并排序列
df2.iloc[1:3,[2,0,1]]
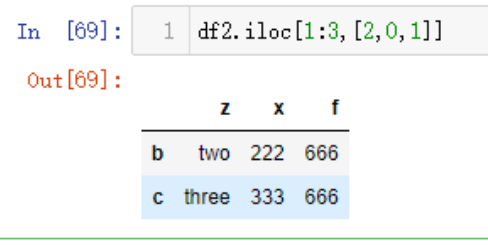
列的引用可以被修改,但是将列表或者数组赋值给一个列时,值的长度必须与DF的长度相匹配,生成一个新列也可以使用这种方法
df2['z']=np.arange(4)
df2
上面的方法要求长度必须匹配,但如果传入一个带有索引的Series时,则不需要,空缺的地方会自动补充缺失
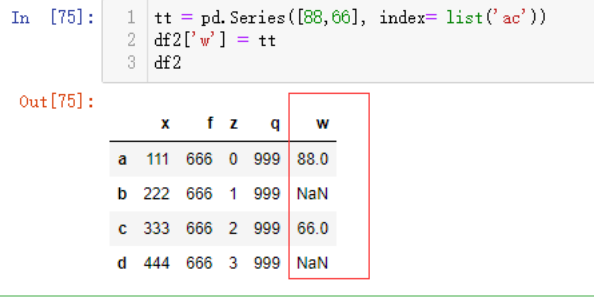
tt = pd.Series([88,66], index= list('ac'))
df2['w'] = tt
df2
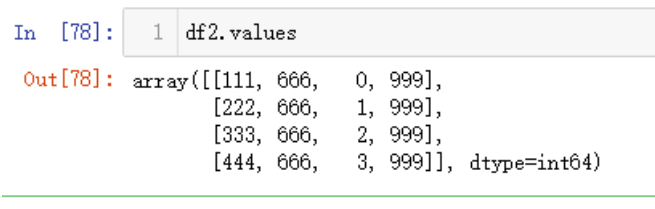
DF中的values属性会将包含在其中的数据以2D ndarray形式返回
df2.values
移除不需要的列,和python一样
del df2['w']
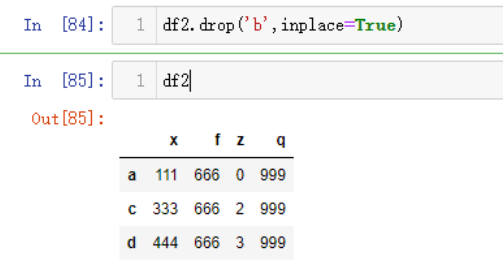
但是移除行时,则需要采用drop函数,drop函数默认在axis=0上操作,返回一个删除值的新对象,所以需要调用inplace参数应用到源数据中
df2.drop('b',inplace=True)
drop也可以删除列,只需修改axis参数值即可。
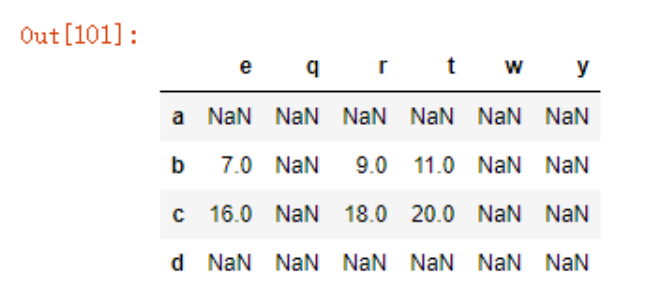
关于运算,两个DF相加时,行和列均对齐的值会进行运算,而未对齐的位置上将产生缺失值,新对象的索引、列是每个DF的索引、列的并集
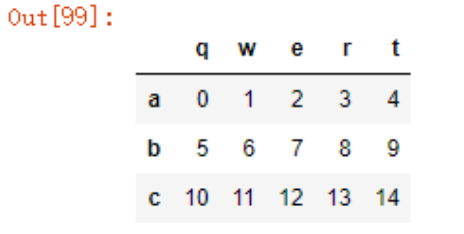
df4 = pd.DataFrame(np.arange(15).reshape((3,5)), index = list('abc'), columns=list('qwert'))
df4
df5 = pd.DataFrame(np.arange(12).reshape((3,4)), index = list('bcd'), columns=list('erty'))
df5

df4+df5