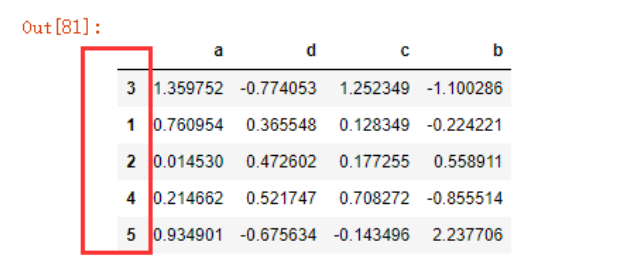
新建测试数据
data4 = pd.DataFrame(np.random.randn(5,4), index =[3,1,2,4,5] ,columns=list('adcb'))
data4
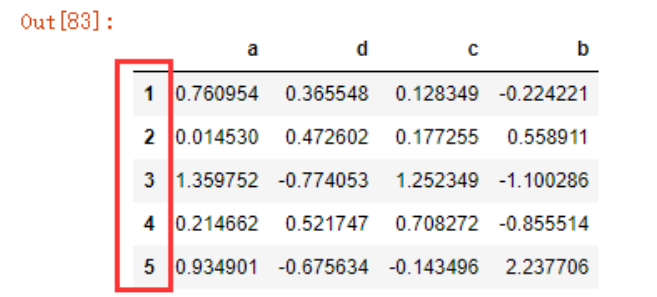
sort_index()默认在0轴上进行排序,返回一个新的、排序好的对象
data4.sort_index(ascending=True)
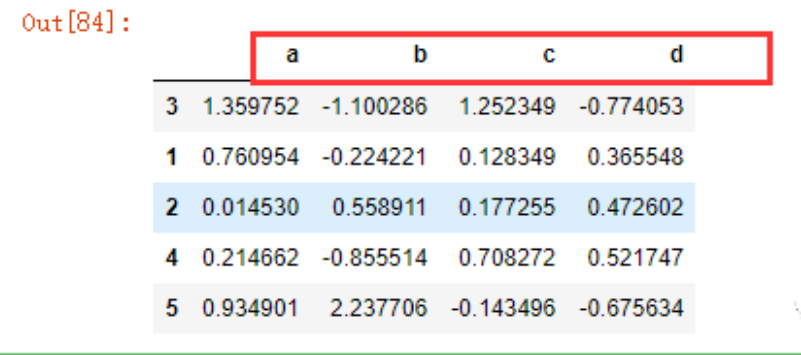
让列排序
data4.sort_index(axis="columns")
如果想要根据某列Series的值进行排序,使用sort_values函数,对多列进行排序时,可以传入一个列表给关键字参数by
data4.sort_values(by='b',ascending=False)
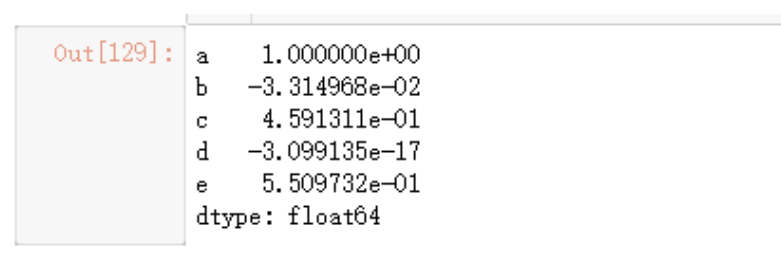
获取排名rank,排名指对数组从1到有效数据点总数分配名次的操作,默认情况下,rank通过将平均排名分配到每个组来打破平级关系,先看下Series的示例:
obj = pd.Series([6,-1,6,5,4,0,4])
obj.rank()

列表里面7个值,按照从小到大序列,6为最后一名,因为存在两个6,所以显示为6.5,可以对它们在数据中的观察顺序来分配排名:
obj.rank(method='first')

在DF中,也是一样的用法,默认在0轴上进行排名:
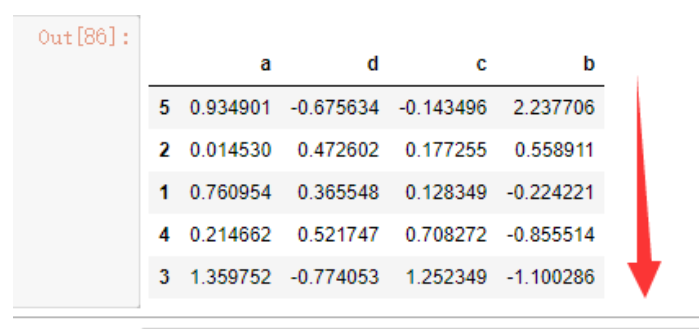
data4.rank()
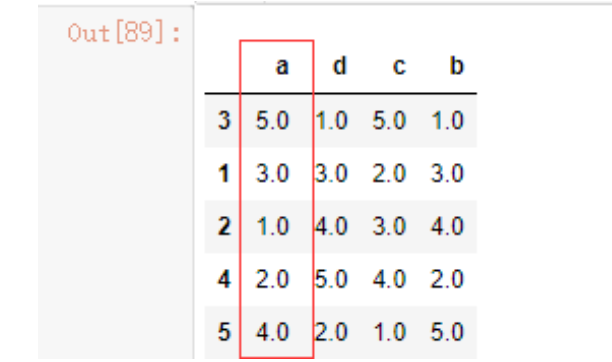
我们可以使用axis参数来改变列的排名
data4.rank(axis=1)
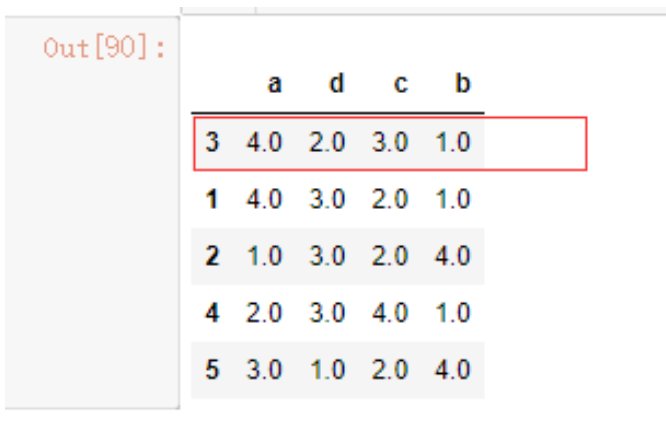
重建索引reindex
reindex默认在0轴上创建一个符合新索引的新对象,如果某个索引值之前不存在,则会引入缺失值。
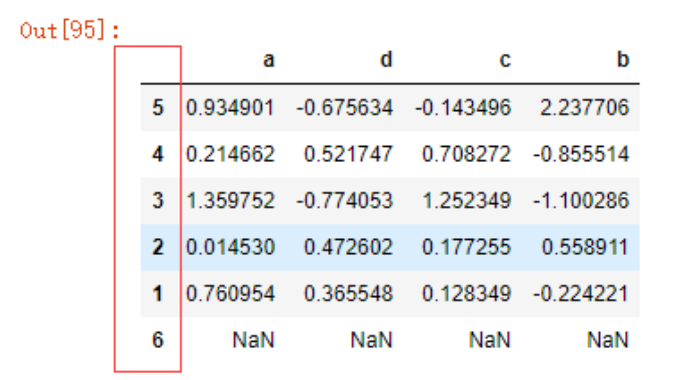
data4.reindex([5,4,3,2,1,6])
data4.reindex(['a','b','c','d'],axis=1)
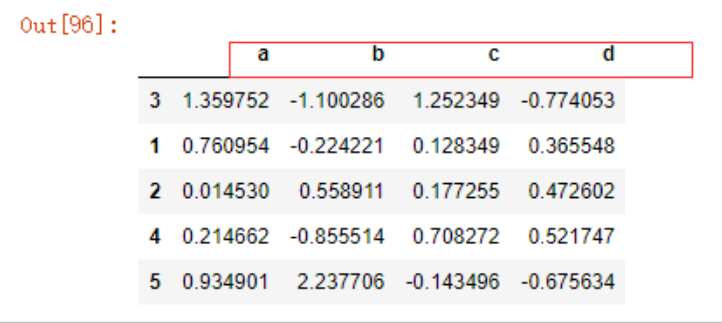
数据的观察与汇总
建立测试数据如下:
data5 = pd.DataFrame(np.random.randn(9,5), columns=list('abcde'))
data5
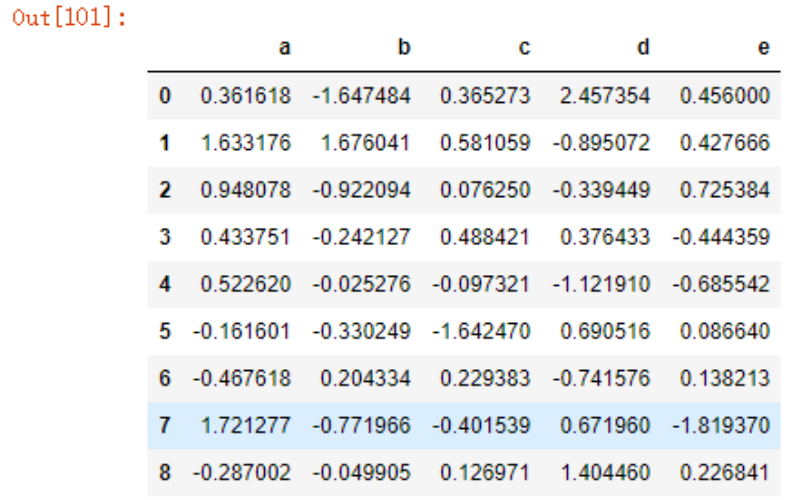
data5.head(2)
data5.tail(2)
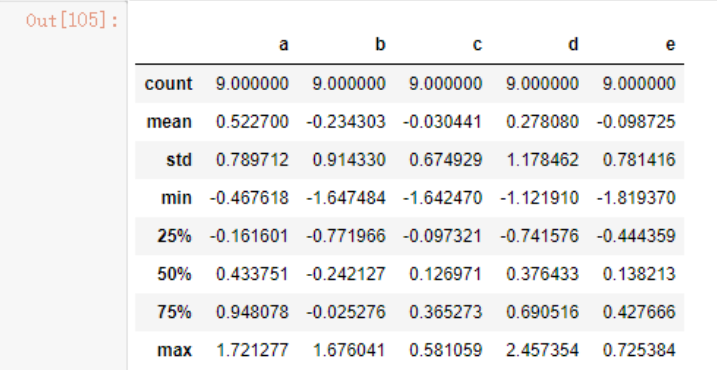
使用describe函数可以很方便的看到数据的大致情况
data5.describe()
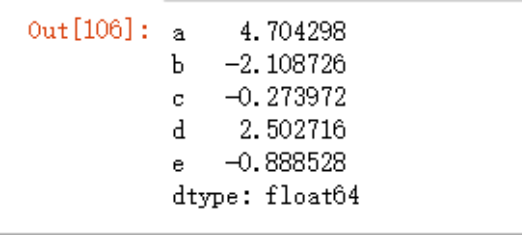
相加等运算,默认还是在行方向
data5.sum()
idxmax返回该行最大值的索引
data5.idxmax()

#获取a列里面的最大值
data5.a[data5.a.idxmax()]
如果获取DF中的唯一值
data6 = pd.DataFrame(np.random.randint(1,5,size=(6,5)), columns=list('abcde'))
data6

可以使用unique函数或者value_counts函数,但是这些函数需要应用在类似Series这种一维数组中,例如
data6.a.unique()
>array([4, 3, 1], dtype=int64)
data6.loc[1].unique()
>array([3, 4, 2], dtype=int64)
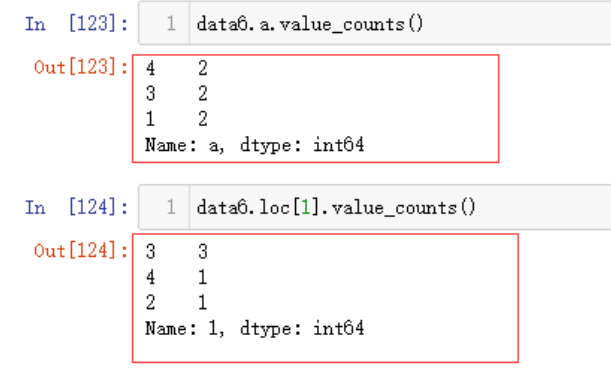
data6.a.value_counts()
data6.loc[1].value_counts()
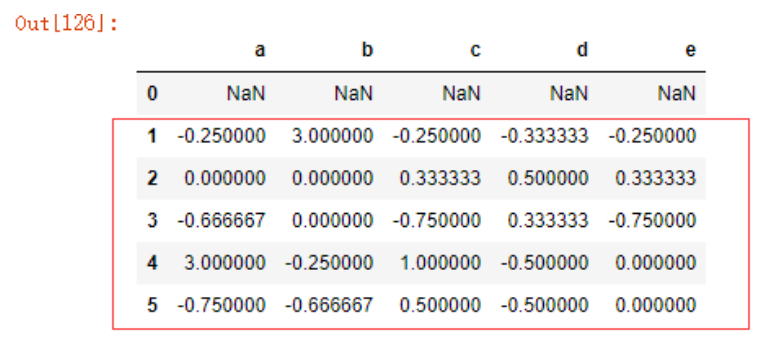
如果想要统计下一行数据相较于上一行数据变化的百分比,pandas也有很便利的函数pct_change,首先我们来看一道简单的算术题,假设一棵树上第一年有1颗果子,第二年长了5颗,那么第二年相较第一年的变化百分比应为(5-1)/1=400%,理解了这个计算方式,我们再来看如下代码就很清晰了
data6.pct_change()
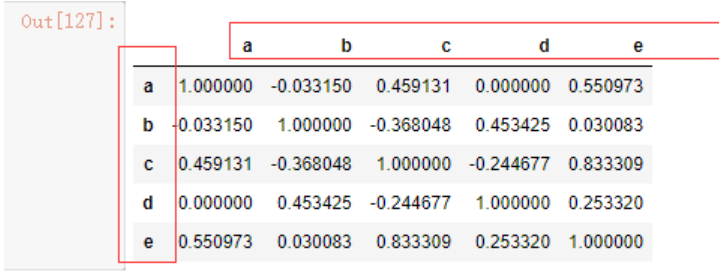
相关系数corr,corr函数计算的是两个Series中重叠的、非NA的、按索引对齐的值的相关性
data6.corr()
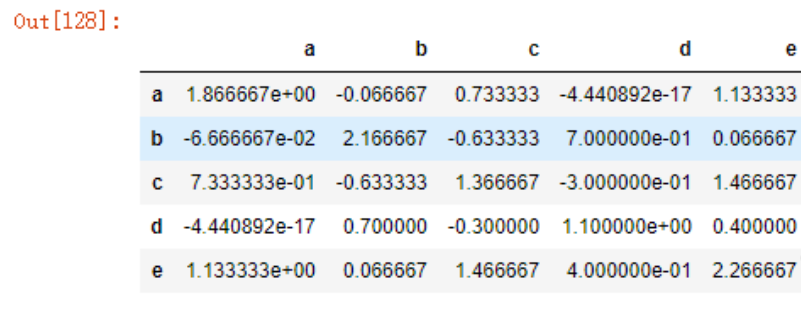
协方差矩阵cov()
data6.cov()
corrwith函数计算出DF中的行或列与另外一个序列或者DF的相关性
data6.corrwith(data6.a)