pandas原本就用于解决现实中遇到的数据问题,其中read_csv的可选参数已经超过了50个,因此,数据的输入和输出是必不可少的。
准备工作,已经在该文件夹下放置了一个csv和xlsx文件用于测试
data = pd.read_csv('./test.csv')
data
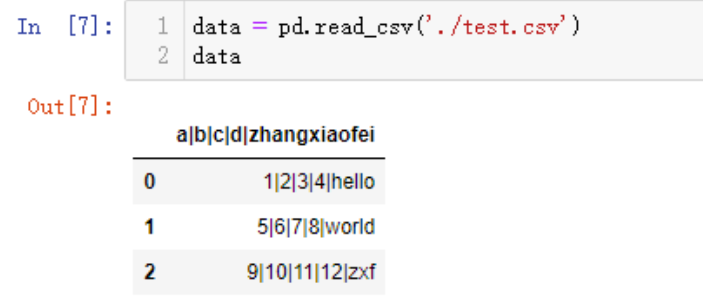
我们可以设定分隔符sep,让数据读取更规范
data = pd.read_csv('./test.csv',sep='|')
data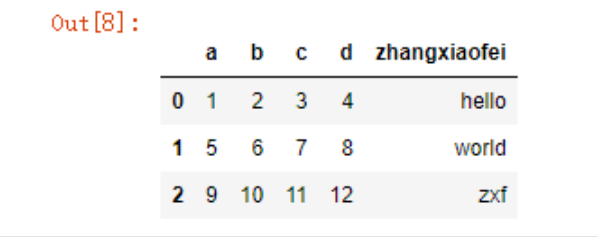
read_table也可以达到同样的效果,但是未来会被遗弃掉,所以了解下就行了,“FutureWarning: read_table is deprecated, use read_csv instead.”
可以看到默认会将数据中的第一行作为列名,如果我第一行就是数据,可以指定header参数取消列名,让pd自动分配列名
data = pd.read_csv('./test.csv',header=None)
data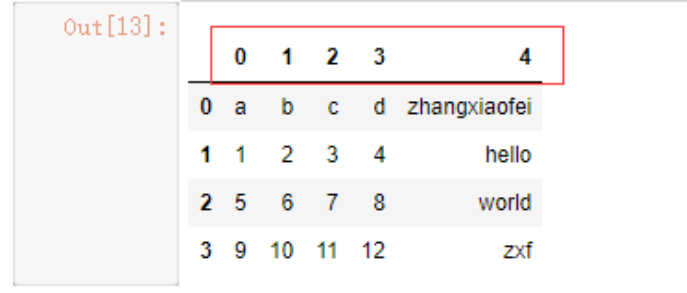
如果想要自定义列名,我们可以利用names参数,但是需要注意,names参数中的长度如果和列数不一致,pd不会报错,而是会将数据列名从前往后依次省略,而当names定义的长度仅比数据的列数少一个时,那么pd会推断第一列应当作为DF的索引!
data = pd.read_csv('./test.csv',names=['this','is','test','column','name'])
data
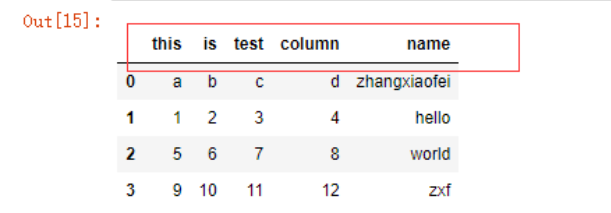
如果想要将数据中的某一列变成DF的索引,可以使用index_col参数
names = ['this','is','test','column','will_transfer_to_index']
data = pd.read_csv('./test.csv',names=names,index_col='will_transfer_to_index')
data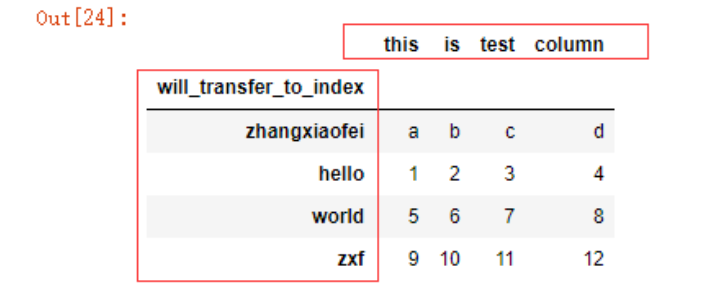
在有些情况下,分隔符并非固定,例如下图中,分隔符是以单个或多个空白格分开
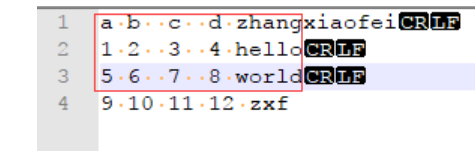
那么当我们还是以空白符读取数据时就会存在问题,例如
data2=pd.read_csv('./test-space.csv',sep=' ')
data2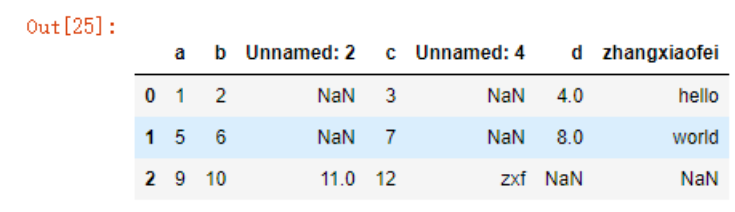
此时,可以向sep参数传入一个正则表达式作为分隔符,问题就很容易解决了
data2 = pd.read_csv('./test-space.csv',sep='\s+')
data2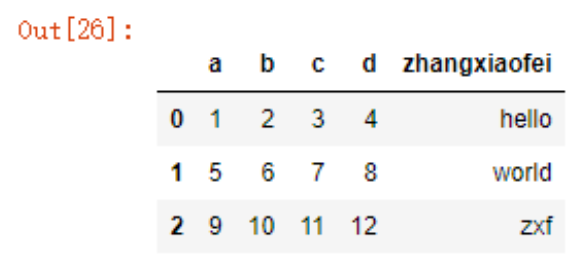
有时候,我们也许会遇到数据当中前几行存在注释或者备注,我们可以使用skiprows参数来跳过这几行,例如原始数据如下
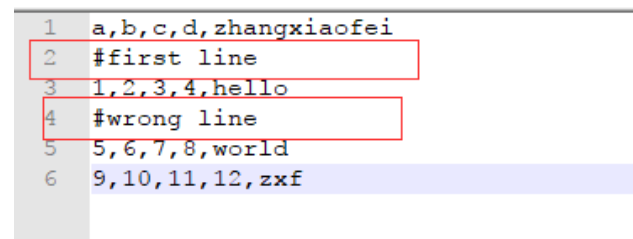
跳过这些注释的行数
data3 = pd.read_csv('./test.csv',skiprows=[1,3])
data3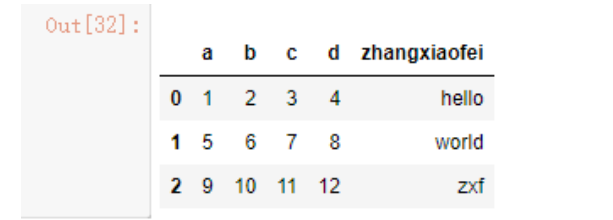
关于缺失值的处理,原始数据如下
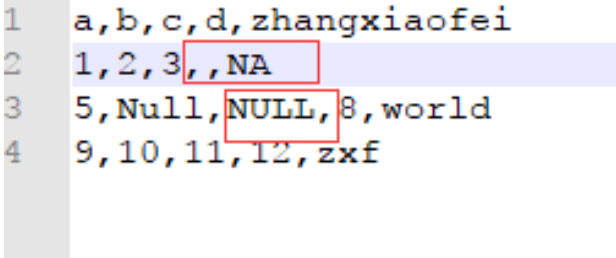
我们使用默认方式读取文件时,会变成下图所示(只有大写的NA和NULL和空白才会被判断为缺失值)
data4 = pd.read_csv('./test.csv')
data4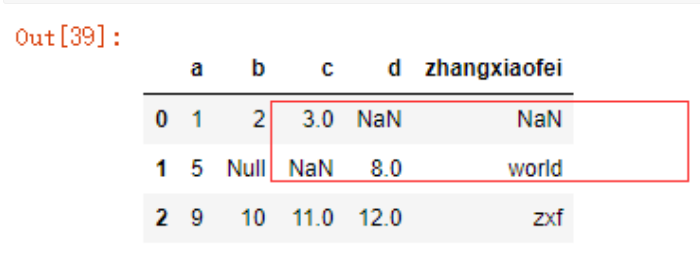
我们可以使用isnull函数来获取是否为缺失值的bool值。
可能在有些情况下,我们的数据中存在的缺失值并非空白、NA、NULL中的一项,例如上方的b列的Null值,这时候就可以使用na_values参数来指定缺失值标识符,下方示例中,我将b列的Null、2值,zhangxiaofei列的zxf值指定为我数据中的缺失值
na_dict = {'b':['Null','2'],'zhangxiaofei':'zxf'}
data4 = pd.read_csv('./test.csv',na_values=na_dict)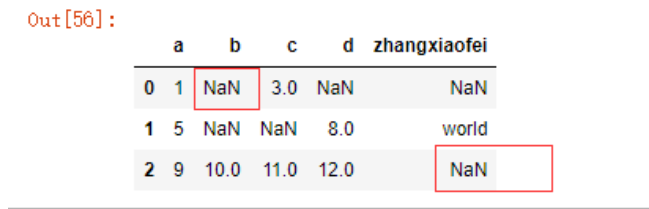
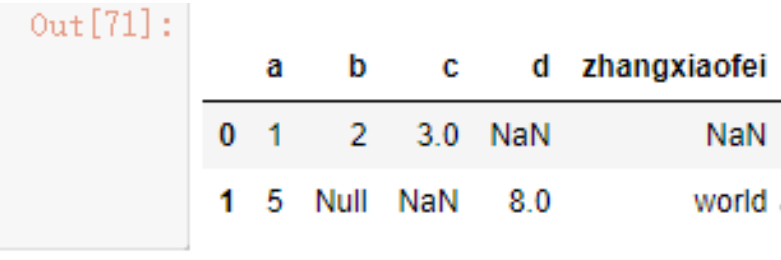
有时候数据量过于庞大,我们可能只想读取几行来看一下,使用nrows参数自定义读取行数
data4 = pd.read_csv('./test.csv',nrows=2)
excel的读取和csv差不多
data5= pd.read_excel('test.xlsx',sheet_name='test')
data5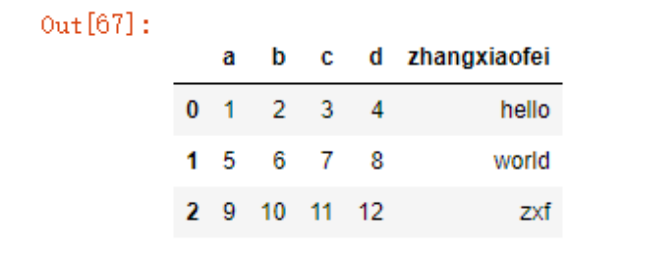
输出文件
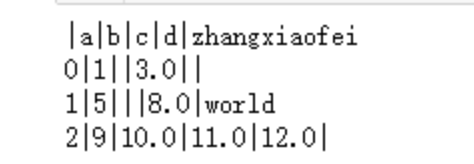
演示输出在控制台上的文本结果,缺失值的展现形式为空字符串
import sys
data4.to_csv(sys.stdout,sep='|')
我们可以使用na_rep参数对缺失值进行标注
data4.to_csv(sys.stdout,na_rep='WHITE')

默认输出的文件中包含了行和列的标签,我们可以禁止输出
data4.to_csv(sys.stdout,index=None,header=None)
或者仅仅写入列的子集,并且自定义顺序
data4.to_csv(sys.stdout,index=False, columns=['a','zhangxiaofei'])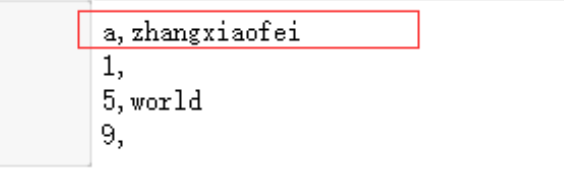
excel的输出很简单
data5.to_excel('test2.xlsx')