pandas中的数据合并常用的方法有两个merge和concat,其中merge方法基于两个df的共同列进行合并,concat用于处理series和df的行拼接或列拼接。
新建测试数据如下:
df1 = pd.DataFrame({'one':['a','a','a','b','b','b','c',],
'data1':range(7)})
df2 = pd.DataFrame({'one':['a','b','d'],
'data2':range(3)})
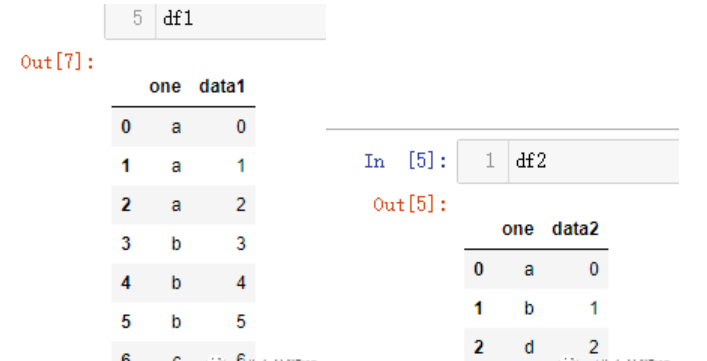
pd.merge(df1,df2,on='one')
pd.merge(df1,df2,on='one',how='inner')# 等价于上面的写法
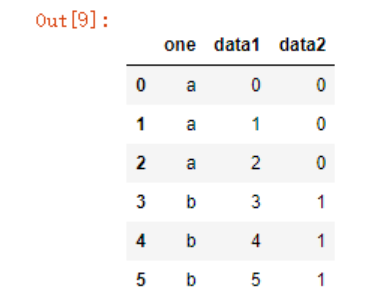
我使用参数on指定了以列one开始聚合数据(参数on指定合并的列名,这个参数需要保证两个dataframe有相同的列名),可以看到默认取了df1和df2中列one的交集a、b。如果想要改变聚合的形式,可以使用how参数来指定,对于聚合指定列没有的值,会以缺失值展现出来
pd.merge(df1,df2,on='one',how='outer')
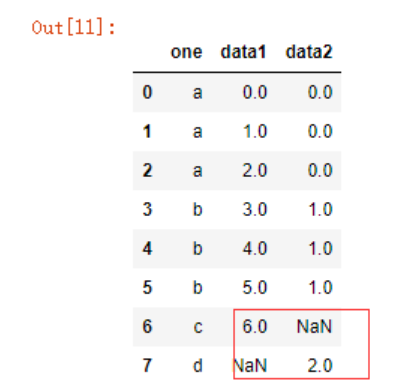
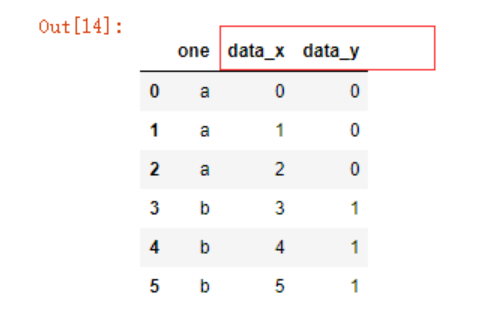
如果两个df的列名均相同,pandas合并时会自动在未指定列名后面增加_y等参数以作区分:
df3 = pd.DataFrame({'one':['a','a','a','b','b','b','c',],
'data':range(7)})
df4 = pd.DataFrame({'one':['a','b','d'],
'data':range(3)})
pd.merge(df3,df4,on='one')
如果两个列名均不相同,使用merge函数合并时就会报错了
MergeError: No common columns to perform merge on.
因为不存在相同列,所以此时我们需要使用left_on和right_on参数指定合并的规则,例如我想左边以data1,右边以data2的值合并
df5 = pd.DataFrame({'one1':['a','a','a','b','b','b','c',],
'data1':range(7)})
df6 = pd.DataFrame({'one2':['a','b','d'],
'data2':range(3)})
pd.merge(df5,df6,left_on='data1',right_on='data2')
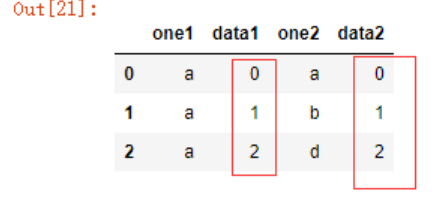
可以看到,data1和data2中的共同值012被筛选出来了,也可以使用how参数来指定并集或者以左边数据为标准等等。
merge还可以指定以索引列为标准进行合并,以left_index和right_index参数控制
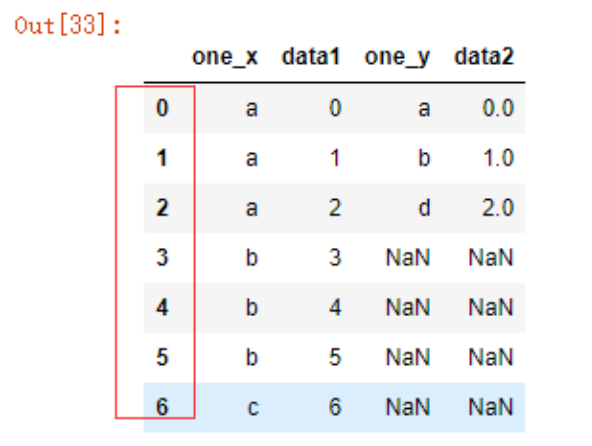
pd.merge(df1,df2,left_index=True,right_index=True,how='outer')
如何在合并数据时以行为扩充?
新建测试数据如下:
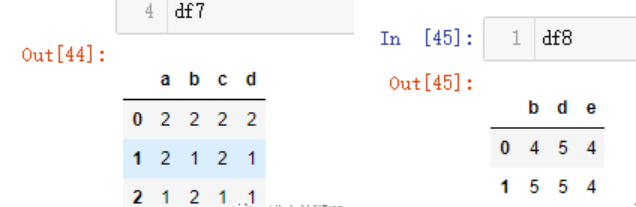
df7 = pd.DataFrame(np.random.randint(1,3,size=(3,4)),columns=list('abcd'))
df8 = pd.DataFrame(np.random.randint(4,6,size=(2,3)),columns=list('bde'))
使用concat函数时需要注意,第一个参数必须是一个可迭代的pandas对象,数据会自动根据列名对齐,对不存在的值返回缺失值
pd.concat([df7,df8],sort=False)
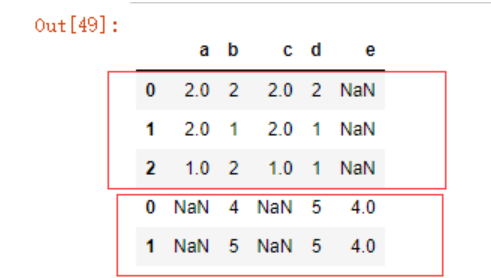
可以看到这还是默认的索引,我们可以舍弃掉原来的索引
pd.concat([df7,df8],ignore_index=True)
数据的清洗
pandas中采用了R语言的编程惯例,将缺失值成为NA(not available),在统计学中,NA数据可以是不存在的数据或者是存在但不可观察的数据(例如数据收集过程中出了问题)。当清洗数据用于分析时,对缺失数据本身进行分析以确定数据收集问题或数据丢失导致的数据偏差通常很重要。
-----Python for Data Analysis
重复值处理。
新建测试数据如下:
dt1 = pd.DataFrame({'k1':['one','two']*3 + ['two'],
'k2':[1,1,2,3,3,4,4]})
dt1

dt1.duplicated()
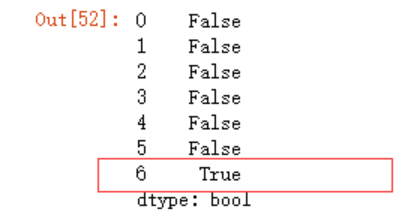
取出非重复值,默认是判断行重复
dt1[~dt1.duplicated()]
和下面的函数等价
dt1.drop_duplicates()
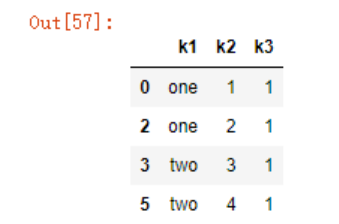
如果想要根据多列来剔除重复值,可传入一个列名列表至drop_duplicates函数
dt1['k3']=1
dt1

剔除k2和k3之间的重复值
dt1.drop_duplicates(['k2','k3'])
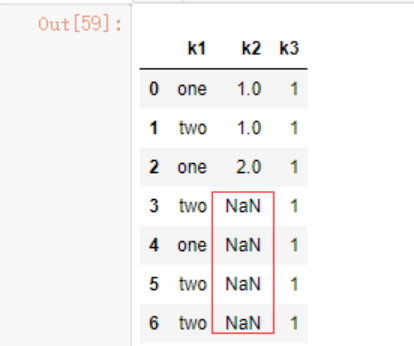
批量替换replace函数。
dt1.replace([3,4],np.nan)
如果想要分别替换成不同的值,除了多次重复这个函数还可以使用一个字典键值对来解决。
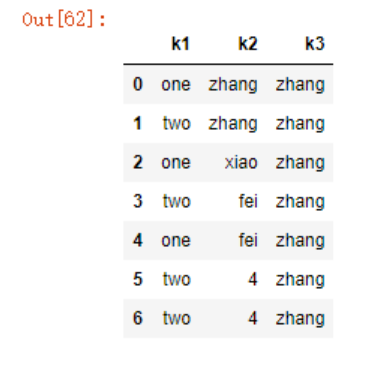
dt1.replace({1:'zhang',2:'xiao',3:'fei'})
缺失值的处理。
过滤缺失值dropna。在Series中比较好理解,示例如下:
dt2 = pd.Series([1,np.nan,2,np.nan])

dt2.dropna()
#两者等价
dt2[dt2.notnull()]
但是对于DF,可能你想删除的是带有缺失值的行或者列,亦或者想删除的全为缺失值或包含缺失值的行、列,情况会有点复杂,先来看下dropna函数默认会怎么处理NA值
建立测试数据
dt3 = pd.DataFrame(np.random.randint(1,high=5,size=(5,4)), \
index=['one','two','three','four','five'],\
columns=list('abcd'))
dt3

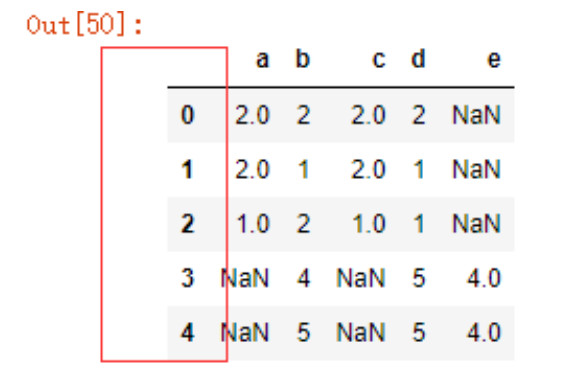
dt3.a=NA # a列为NA
dt3.loc['three']=NA #索引为three的设置为NA
dt3.iloc[4,-2:]=NA #第5行的倒数两列设置为NA
dt3['e']=np.arange(5)
dt3.loc['six'] = np.arange(5,10)
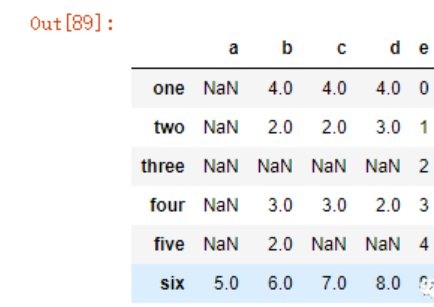
dt3
dt3.dropna()

可以看到,dropna默认会删除包含NA的行,我们可以使用how参数来定义只有当所有值均为NA时,才进行剔除
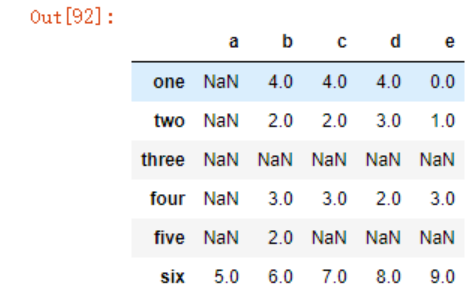
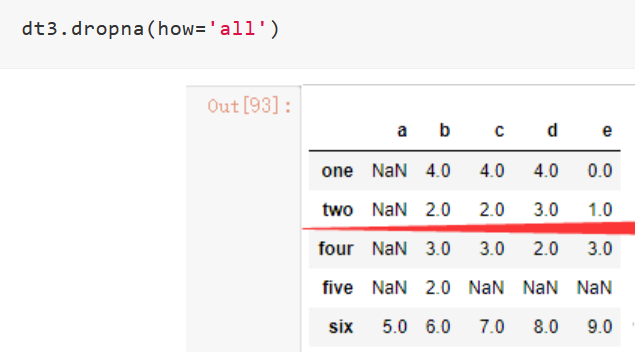
dt3.dropna(how='all')
对列进行处理,只需传入axis=1即可,操作方式是一样的
假如需要保留一定数量的缺失值进行观察,则可以使用thresh参数,可以理解成有效值数量(require that many non-NA values)。
示例如下
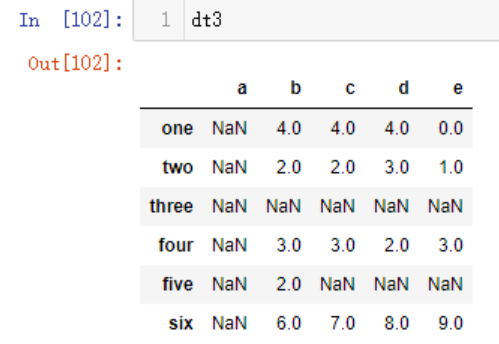
dt3.dropna(thresh=1)
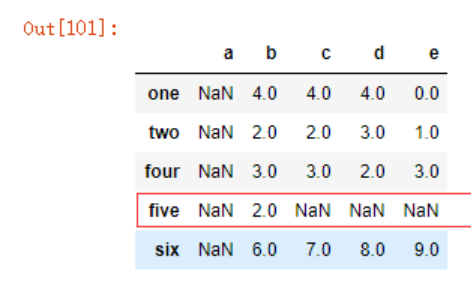
可以看到索引为‘three’的那一行被剔除,而‘five’则被保留下来,因为我设置了thresh=1,即每一行中有效值数量必须大于或等于1。
如何补全缺失值?
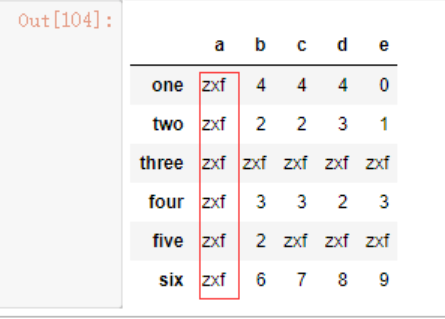
可以使用fillna函数,返回一个新的对象。
dt3.fillna('zxf')
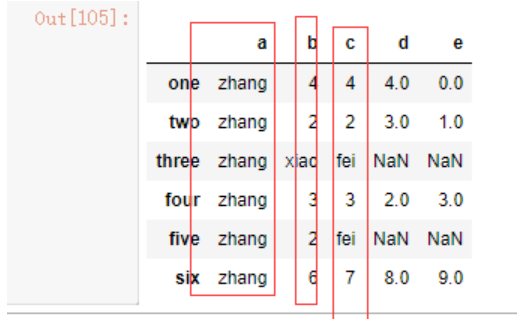
类似前面的replace函数,我们可以传入一个字典,让不同列的缺失值替代项各不相同。
dt3.fillna({'a':'zhang','b':'xiao','c':'fei'})
我们也可以使用method参数让数据根据上下行的内容自动填充
dt3.fillna(method='bfill')

参考:https://www.cnblogs.com/keye/p/10791705.html