python内建的方法对于操作字符串和文本很便利,而在pandas中,是可以将python中的字符串方法和正则表达式应用到整个数据数组中。
在pandas中替换数据内容的某些值。
尽管在上一篇文章中使用了replace函数替换数据内容,但那种替换是针对整个数据来替换,而非元素级别,如下例,我想将baidu.com中的baidu替换成sougou,之前的那种方法就不可行了
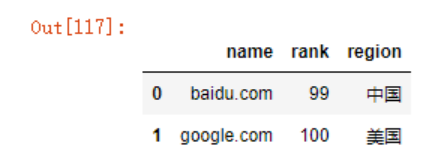
df1 = pd.DataFrame({'name':['baidu.com','google.com'],
'rank':[99,100],
'region':['中国','美国']})
df1
如需替换,只需在前面增加str属性
df1.name.str.replace("baidu",'sougou')

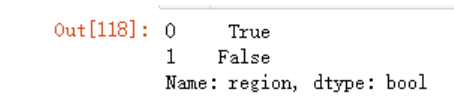
如果我想要筛选地区包含‘中’字的数据内容,可以使用contains函数
df1.region.str.contains('中')
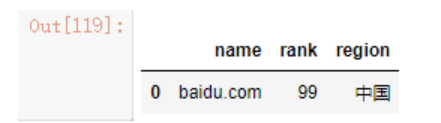
再利用布尔索引将对应的行选取出来,pandas确实强大
df1[df1.region.str.contains('中')]
一般的字符串函数都可以使用,例如
df1.name.str.upper()
df1.name.str.title()
使用函数或映射进行数据转换。Series的map方法接收一个函数或一个包含映射关系的字典型对象,如下例中,我想将每个网站对应的国家添加到DF中
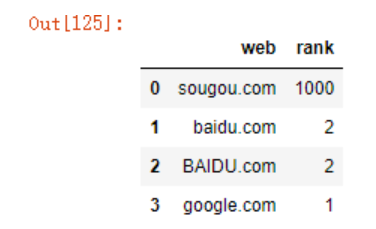
df2 = pd.DataFrame({'web':['sougou.com','baidu.com','BAIDU.com','google.com'],
'rank':[1000,2,2,1]})
df2
region_dict中存放了对应的网站-国家映射关系,我可以直接传入到Series中
region_dict = {
'sougou.com':'China',
'baidu.com':'China',
'google.com':'USA'
}
df2.web.map(region_dict)

可以看到映射正确,至于为什么会有一个NaN,是因为原始的数据中存在一个大写的BAIDU,我们可以在传入映射之前时使用str函数对Series里面的数据进行标准化处理,例如
df2.web.str.lower().map(region_dict)
我们也可以写入一个匿名lambda函数到map函数中一次性解决
df2.web.map(lambda x:region_dict[x.lower()])
例如我们想将某一列首字母大写
df2.web.map(lambda x:x.title())

对于dataframe,可以使用apply函数进行向量化处理,新建测试数据如下
df3 = pd.DataFrame(np.random.randint(1,5,size=(4,5)),\
index=['one','two','three','four'],\
columns=list('abcde'))
df3

df3.apply(np.cumsum)

例如我想要获取每一列中的最大值减去最小值的结果
df3.apply(lambda x:(x.max() - x.min()))
如果想要对列进行处理,则设置axis参数即可。
apply用于对行或者列进行操作,使用applymap可以对DF中的元素进行操作。
df3.applymap(lambda x:x+100)
