定义:通俗的说,离散化是在不改变数据相对大小的条件下,对数据进行相应的缩小。在一些问题中,我们只关心n个数字之间的相对大小关系,而不关心它们具体是多少。因此,我们可以用一种叫离散化的技术来将数字映射到 1 ∼ n 的整数, 从而降低问题规模,简化运算。
连续值经常需要离散化,或者分离成“箱子”进行分析,先来看一个简单的例子,我想将年龄按照15-30,30-45,45-60进行划分分组,可以使用cut方法
ages = np.random.randint(20,60,size =(20))
ages
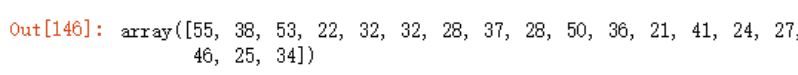
bins = [15,30,45,60]
cats = pd.cut(ages,bins)
cats

pd.cut返回的对象是一个特殊的Categorical对象。我们可以把它当做一个表示箱名的字符串数组,它在内部包含一个categories (类别)数组,它指定了不同的类别名称以及codes属性中的ages数据标签
cats.codes
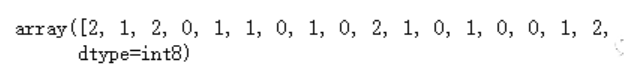
cats.categories

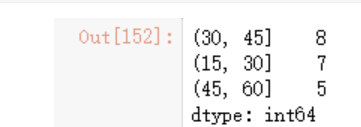
我们可以使用value_counts函数统计出箱的数量
pd.value_counts(cats)
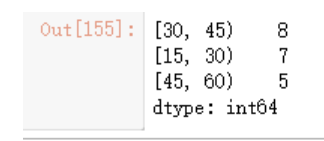
这个统计看着有点不习惯,可以使用right=False来修改统计区间
cats = pd.cut(ages,bins,right=False)
pd.value_counts(cats)
我们也可以在cut函数中传入自定义的labels标签
cats = pd.cut(ages,bins,\
labels=['young','middle','old'])
pd.value_counts(cats)

上面我是已经定义好了箱子bins的分布情况,但是我们也可以传递整数个箱来代替显式的箱边,pandas会根据数据中的最大值和最小值计算出等长的箱,示例如下
data = np.random.randn(100)
pd.cut(data, 4, precision=2)

pd.cut(data, 4, precision=2).value_counts()

通过对上面的cut函数的演示,我们可以看到cut通常不会使每个箱具有相同数据量的数据点,而当我们想让样本在每个箱里面的分布数量相等时,就可以考虑使用qcut函数了,qcut函数基于样本分位数进行分箱(Quantile-based discretization function.),前面的q指代的就是Quantile(分位数)。由于qcut使用样本的分位数,所以可以通过qcut获得等长的箱:
data = np.random.randn(100)
cats = pd.qcut(data,q=4)
cats

pd.value_counts(cats)

可以看到数量确实被等分了。
qcut函数的参数q不仅仅可以使用int类型,还可以使用自定义的分位数,即类似列表的浮点数(list-like of float),范围在0和1之间(包括边),表示每个箱想要分配的数量百分比,例如,我想要分4个箱,第一个箱分配30%的数量,二箱20%,三箱40%,四箱10%:
pd.qcut(data, [0,0.3,0.5,0.9,1]).value_counts()
