数据分析少不了对数据进行分组、统计。分组运算,一般是对数据的某一个分组键进行拆分(分成几组),在拆分的分组上应用某一个函数或者运算,最后把运算结果合并起来。需要注意,分组键需要与拆分的对象长度相同。
制作测试数据如下:
samples = 7
df = pd.DataFrame({"seller":np.random.randint(0,3,size=samples),
"item":np.random.randint(0,3,size=samples),
"price":np.random.randint(1,15,size = samples),
"weight":np.random.randint(5,9,size=samples)})
df["seller"] = df["seller"].map({0:"李大妈",1:"王大爷",2:"宋大妈"})
df["item"] = df["item"].map({0:"白菜",1:"萝卜",2:"青椒"})
df["weight"] = df["weight"].map(lambda x:x*10)
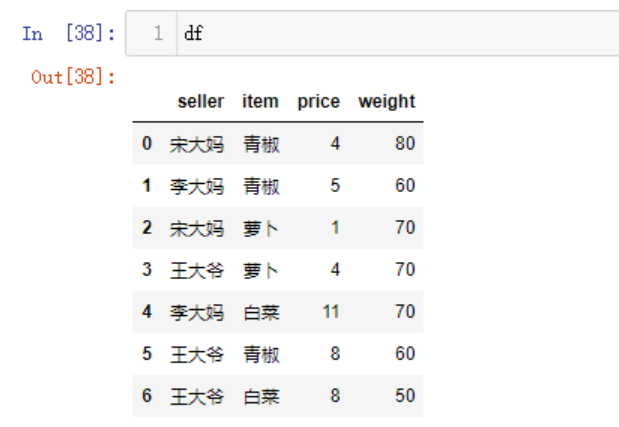
df
假如我想要这些大爷大妈的平均体重,按照上面所述,先聚合分组键大爷大妈,获得DataFrameGroupBy 对象:
df.groupby('seller')
><pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000157724A6508>
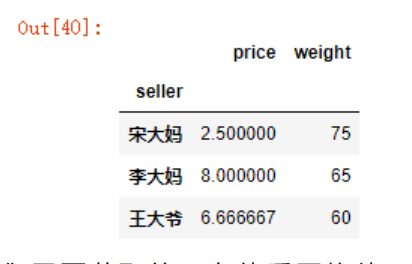
如果此时我们在DataFrameGroupBy分组上应用函数,得出来的是一个DF对象,如下例所示:
df.groupby('seller').mean()
但因为我们需要获取的只有体重平均值,所以,还需要往下取值,获得一个SeriesGroupBy对象
df.groupby('seller')['weight']
><pandas.core.groupby.generic.SeriesGroupBy object at 0x0000015774923CC8>
获取运算结果
df.groupby('seller')['weight'].mean()

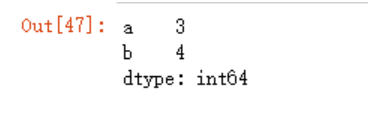
只要分组键与拆分的对象长度相同,即可聚合,所以我们新建一个数组来做下测试:
df.groupby(np.array(list('abbabba'))).size()
我们也可以使用apply函数来应用自定义的函数,例如,我现在想计算出超市里宋大妈,李大妈,王大爷体重最大值与其各自的体重差,代码如下
df.groupby('seller')['weight'].apply(lambda x:(x.max() - x))
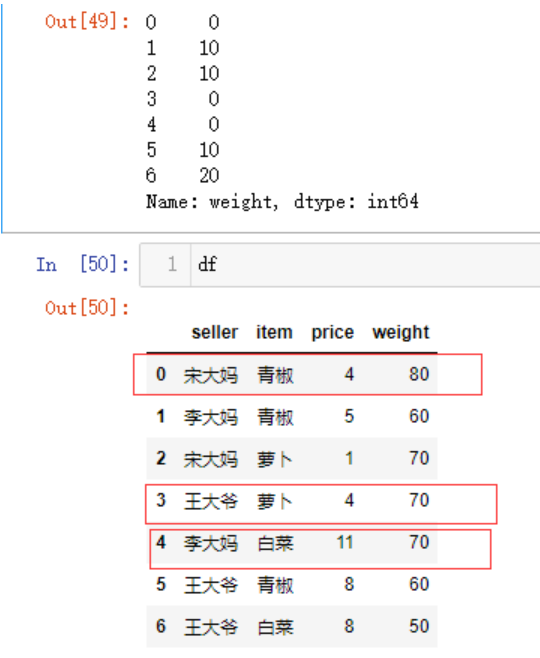
可以看到索引为0的值为0,索引为0的宋大妈,其体重最大值为80,相减为0,索引为1的李大妈,其体重最大值为70,相减为10,以此类推。
关于多层索引的重塑,有两个概念,stack(堆叠),该操作会“旋转”或将列中的数据透视到行;unstack(拆堆),该操作会将行中的数据透视到列。
新建测试数据
samples = 7
df = pd.DataFrame({"seller":np.random.randint(0,3,size=samples),
"item":np.random.randint(0,3,size=samples),
"price":np.random.randint(13,15,size = samples),
"weight":np.random.randint(7,9,size=samples)})
df["seller"] = df["seller"].map({0:"李大妈",1:"王大爷",2:"宋大妈"})
df["item"] = df["item"].map({0:"白菜",1:"萝卜",2:"青椒"})
df["weight"] = df["weight"].map(lambda x:x*10)
df
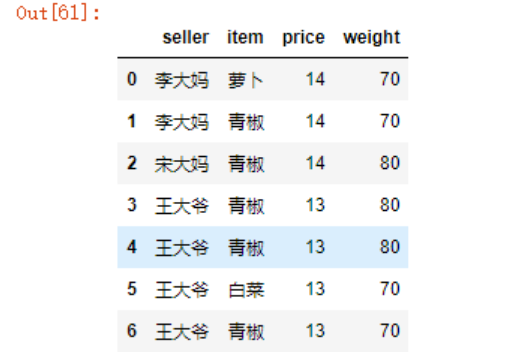
df.groupby(['seller','price']).size()

运用unstack函数可以将内层索引值转换为列名,形成DataFrame
df.groupby(['seller','price']).size().unstack()
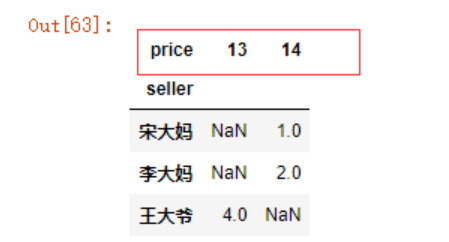
type(df.groupby(['seller','price']).size())
>pandas.core.series.Series
type(df.groupby(['seller','price']).size().unstack())
>pandas.core.frame.DataFrame
运用stack函数可以将DF转化成多层索引的Series
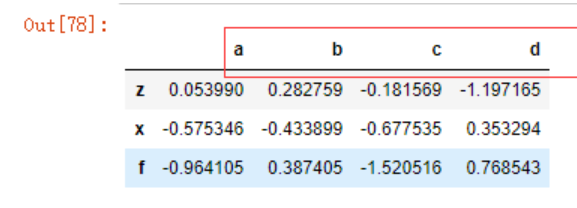
data = pd.DataFrame(np.random.randn(4,3),
index= list('abcd'),
columns=list('zxf'))
data
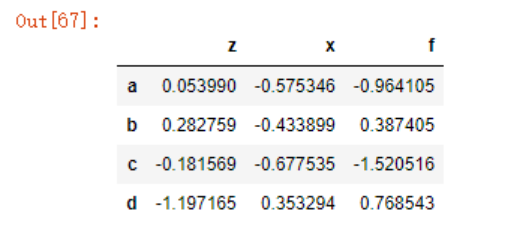
data.stack()

type(data.stack())
>pandas.core.series.Series
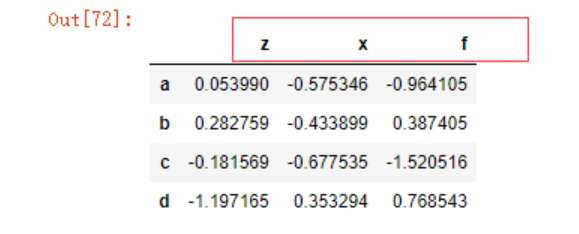
在使用unstack函数时默认会转换内层索引(level=-1),示例如下
data.stack().unstack()
但我们也可以指定level=0,让其根据外层索引旋转
data.stack().unstack(level=0)
数据分析实例
使用的是githut上面一个开源的小费数据集,因为一些原因,即使安装了seaborn库,也无法在线加载这个数据集,所以,从源地址下载了tips.csv数据集,下载地址在下方参考中。
目的:希望通过这份数据集来分析性别、账单金额等因素对于小费的影响等等。
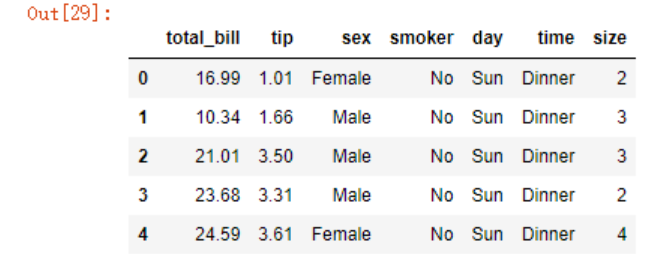
data = pd.read_csv('./tips.csv')
data.head()
先用唯一值来看下有多少天、早午晚餐等等
data.day.unique()
>array(['Sun', 'Sat', 'Thur', 'Fri'], dtype=object)
data.time.unique()
>array(['Dinner', 'Lunch'], dtype=object)
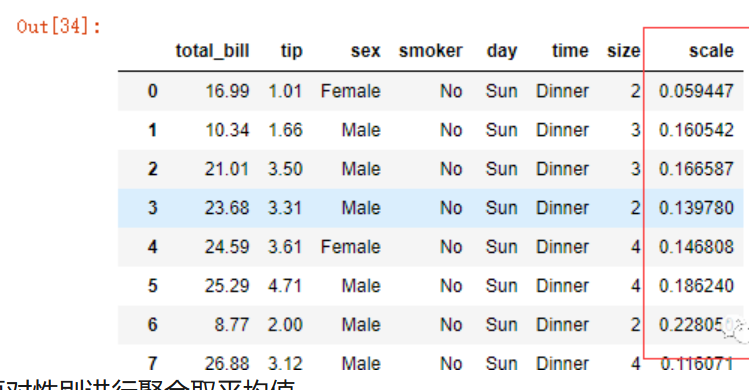
男士和女士给出的小费比例,首先我们需要知道这个小费的比例是多少,比例=小费/账单金额:
data['scale'] = data['tip']/data['total_bill']
data
再对性别进行聚合取平均值
data.groupby('sex')['scale'].mean()

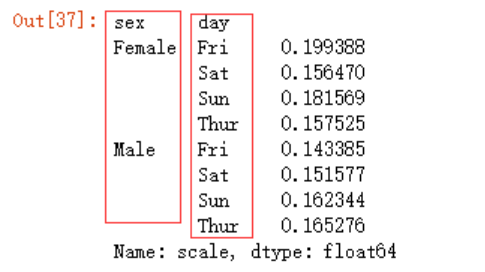
如果想知道男性和女性在不同的日期给小费的比例(两个分组)
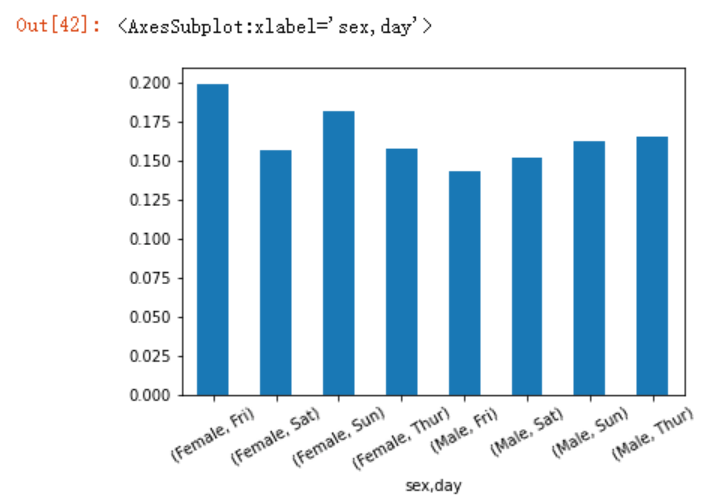
data.groupby(['sex','day']).scale.mean()
我们也可以通过图形将其更为直观的展现出来
data.groupby(['sex','day']).scale.mean().plot.bar(rot=30)
参考
#pandas中数据聚合
https://www.cnblogs.com/kuangkuangduangduang/p/10277006.html
# tips.csv
https://github.com/mwaskom/seaborn-data