以下数据源来自于互联网公开的北京二手房成交数据,仅作个人学习使用。
目的:
- 分析北京二手房成交价格分布
- 寻找每个版块成交总金额超过1亿的经纪人
- 分析成交量超过1亿的经纪人相关因素
数据的读取与合并
文件夹,一共有7份文件,所以肯定涉及到合并数据集,
data_list = []
for i in range(1,8):
try:
_ = pd.read_csv(f'./lianjia/lianjia{i}.csv')
except:
_ = pd.read_csv(f'./lianjia/lianjia{i}.csv',encoding='gbk')
finally:
data_list.append(_)
data = pd.concat(data_list)
data.head()
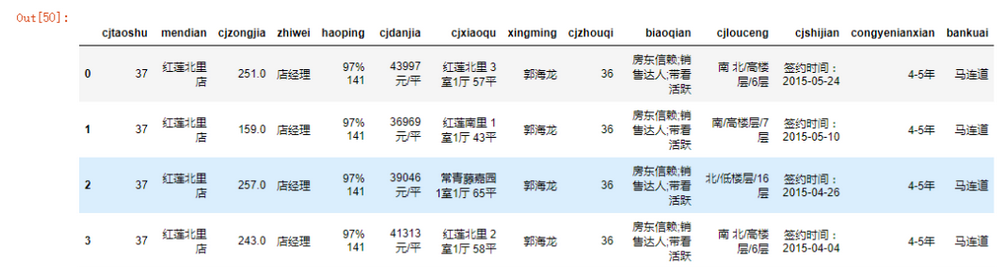
数据类型的转换
可以看到数据的成交单价是*元/平,对数据分析并不友好,我们可以转换数据类型,让我们看的更加清楚。
先来看下数据的各字段类型。
data.info()
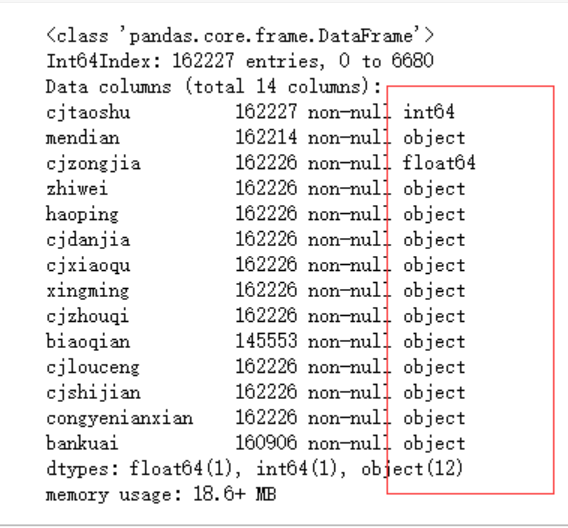
对数据某一列的处理,可以使用str的replace函数或者是Series的map函数,参考 数据清洗之字符串处理与应用函数处理数据 。
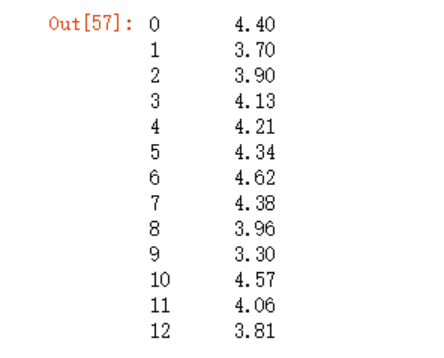
先来看下第一种
round(data.cjdanjia.dropna().str.replace("元/平","").astype('float')/10000, 2)
第二种方法
data.cjdanjia.dropna().map(lambda x:round(float(x.replace("元/平",""))/10000,1))

看下最大值和最小值,最小值为0的不要
dj.max()
dj = dj[dj>0]
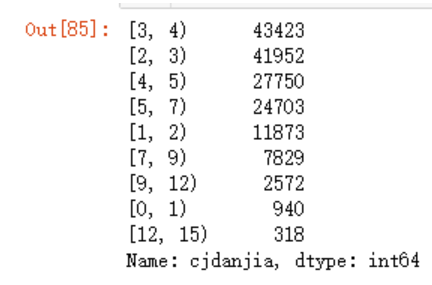
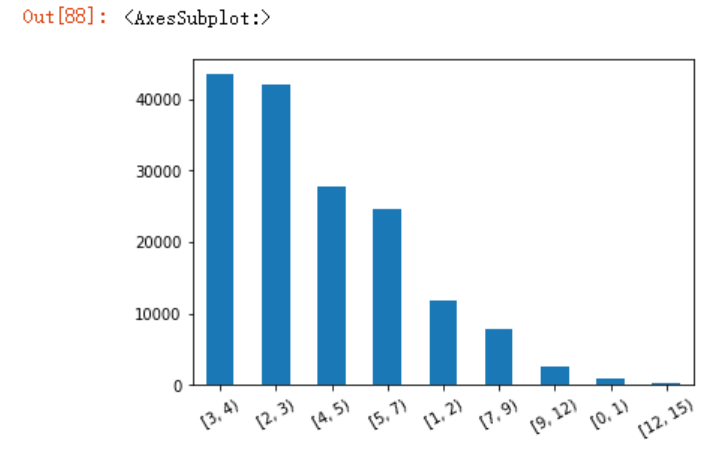
此时,我们可以进行离散化分析了,
bins = [0,1,2,3,4,5,7,9,12,15]
pd.cut(dj,bins,right=False)

cats = pd.cut(dj,bins,right=False)
pd.value_counts(cats)
我们还可以利用pandas绘图
pd.value_counts(cats).plot.bar(rot=30)
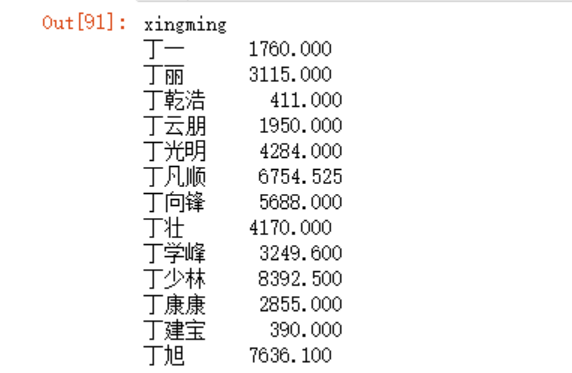
分组运算-寻找每个板块成交金额超过1亿的经纪人
先来看下每个经纪人的总金额汇总
data.groupby('xingming')['cjzongjia'].sum()
此时这个Series我们可以获得其布尔值
jiren_zongjia>10000
但是需要注意的是,现在就不是在原来的data中取名字了,一开始我老是习惯使用data[jiren_zongjia>10000]来取值,结果报错:
IndexingError: Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match
大意就是这个布尔值数据的索引和原始数据索引不匹配!确实不匹配啊,因为布尔索引的取值经过了聚合,怎么可能会和原始数据源一致呢?正确的方法如下
jiren_zongjia[jiren_zongjia>10000]
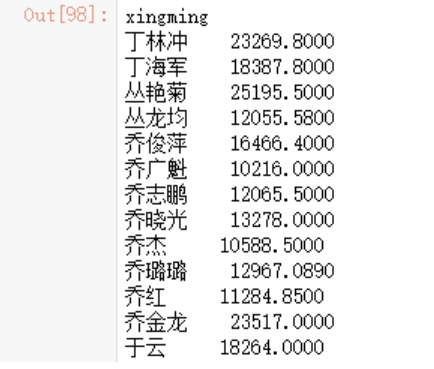
那么如何去获得每个板块中超过1亿金额的经纪人呢?这相当于两个聚合的问题,也是一样的解决方案
x = data.groupby(['bankuai','xingming'])['cjzongjia'].sum()
x
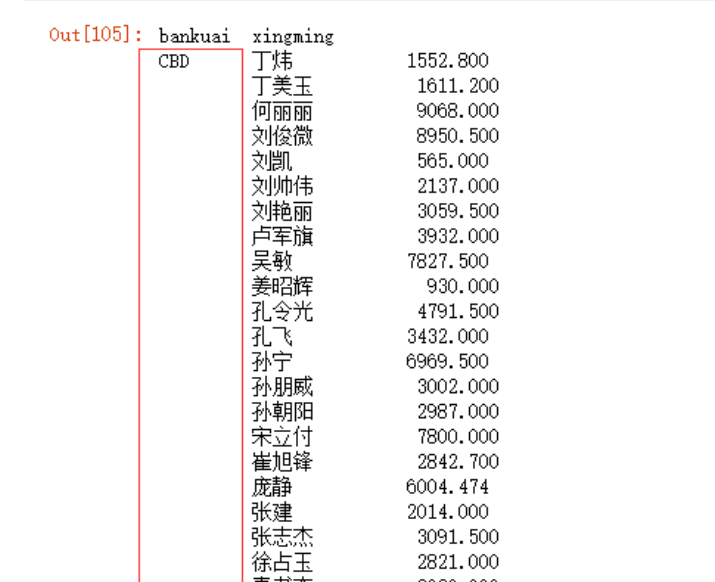
x[x>10000]

透视表-分析成交量超过1亿的经纪人相关因素
透视表,动态的去改变表的布局,方便我们分析数据,比如说,重新去指定表的行或列。函数为pivot_table,先来看下它的介绍:
Create a spreadsheet-style pivot table as a DataFrame.
创建一个电子表格样式的数据透视表作为 DataFrame。
相关参数:
Signature:
data.pivot_table(
values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All',
observed=False,
sort=True,
) -> 'DataFrame'
第一个,即需要聚合的列
values : column to aggregate, optional
第二个,index指定的索引
第三个,columns指定的列名
第四个,aggfunc指定对聚合数据应用的函数
第五个,fill_value指定对缺失值应用的值
先看下最简单的示例:
data.pivot_table(values='cjzongjia',index='xingming')

稍微复杂一点的,想要筛选出所有经纪人的成交总金额和年份的关系:
data.pivot_table(values='cjzongjia',
index='xingming',
columns=['congyenianxian'],
aggfunc="sum")
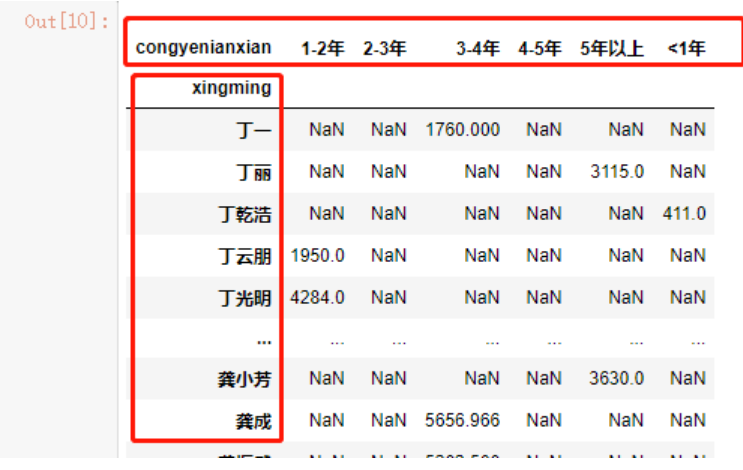
我们现在可以获取到经纪人的成交总金额是否超过1亿了
data_nx > 10000

因为False在python中为0,True在python中为1,所以将每一列,例如1-2年、2-3年等等的数值相加,则可以获取从业年限1-2年,2-3年,3-4年等超过1亿的人数各有多少。
(data_nx > 10000).sum()
#等价于 np.sum(data_nx > 10000)

因为sum函数默认是在轴0上进行计算,即计算行与行之间的和,所以不用修改axis值。
照例,来个图形
np.sum(data_nx > 10000).plot.pie()
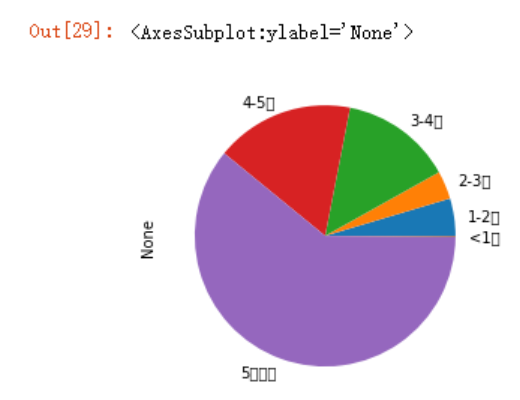
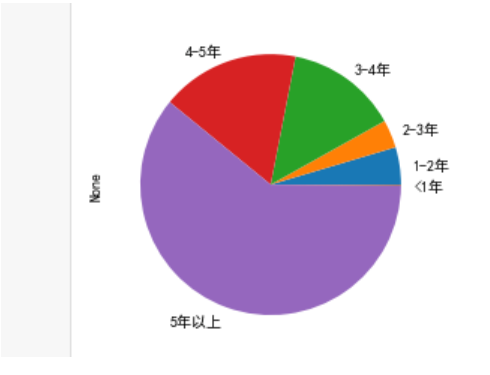
可以看到matplotlib绘图无法显示中文标签,解决代码如下
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
np.sum(data_nx > 10000).plot.pie()
对分组应用自定义函数
先来看下数据,在聚合取值时,多一个中括号可以显示为DataFrame,如下面的第二种写法
data.groupby('bankuai')['cjdanjia'].mean()
data.groupby('bankuai')[['cjdanjia']].mean()
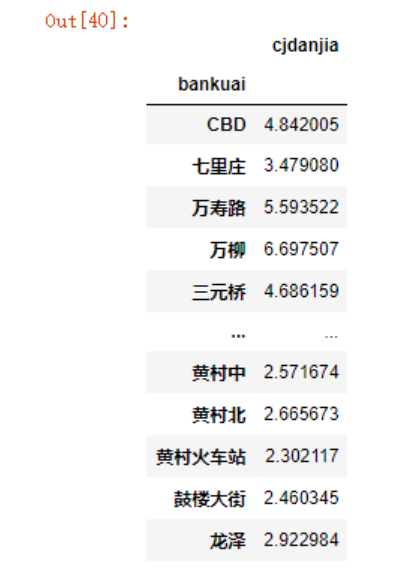
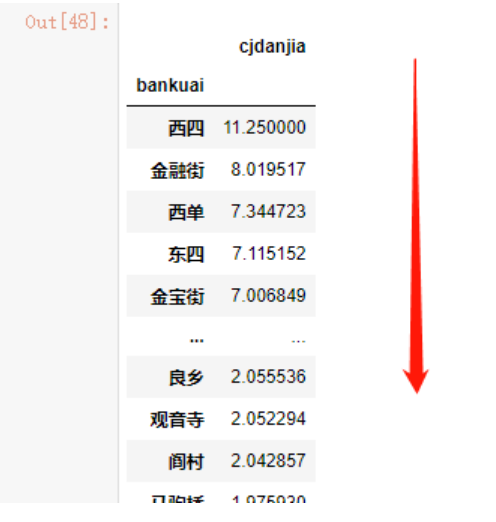
假如我现在想要对均价进行排序,可以使用sort_values函数
data_1 = data.groupby('bankuai')[['cjdanjia']].mean()
data_1.sort_values(by='cjdanjia',ascending=False)
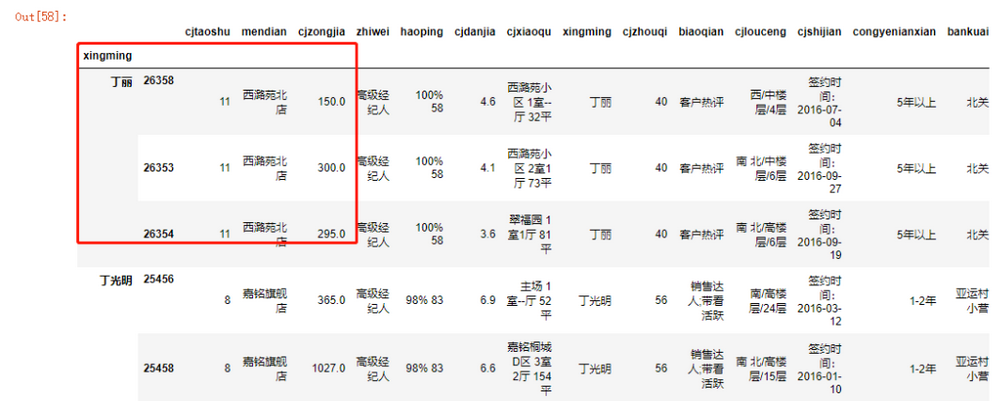
现在假设有个需求,需求每个经纪人成交单价最高的前5套房子记录。之前在数据清洗之字符串处理与应用函数处理数据一文中介绍了DataFrame可以通过apply函数对行与列进行向量化处理,而data.groupby('xingming')是一个DataFrameGroupBy,也可以通过apply函数来应用自定义的函数。
def top(group, n=3):
return group.sort_values(by = 'cjdanjia',ascending=False)[:n]
data.groupby('xingming').apply(top)
参考
https://www.cnblogs.com/onemorepoint/p/8425300.html