以下数据源来自于互联网公开的北京二手房成交数据,仅作个人学习使用。
在建模时,70%的时间用于清洗数据都是很正常的。
目的:想要通过对2015年成交量排名前15的小区位置、面积和楼层朝向分析来完成对房子单价的预测。
数据的预处理-特征选取
数据合并,先看下数据的大概情况
data.head()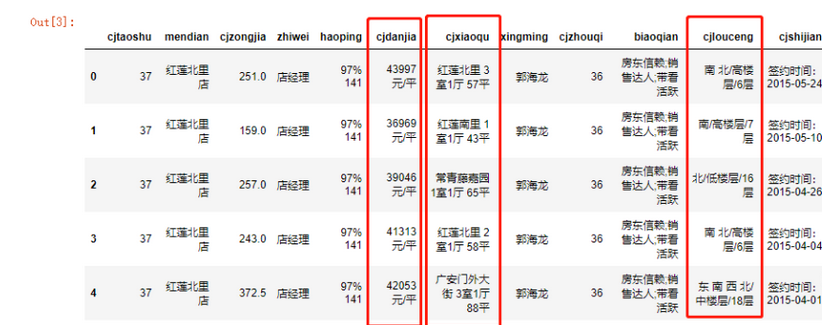
data.info()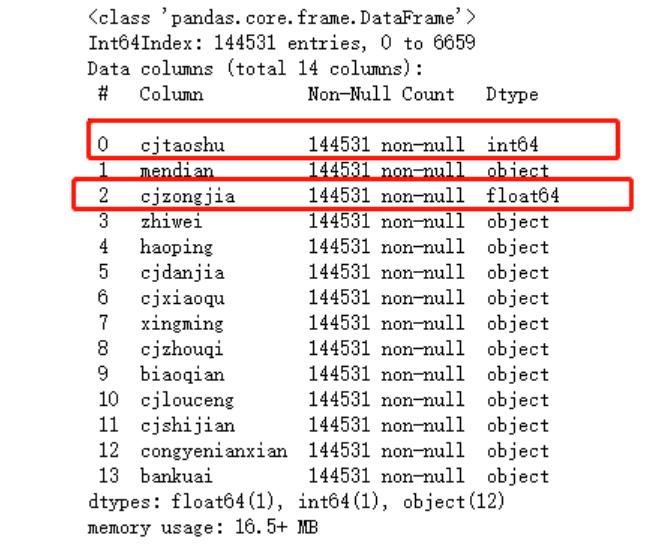
首先,从数据中选取出我想要的特征(2015年),常规做法如下
#先建立时间序列
data['times'] = data.cjshijian.str.replace("签约时间:","")
#字符串转为时间格式
data.times = pd.to_datetime(data.times)
#设置时间索引
data.set_index(data.times, inplace=True)
一定要注意!!!先将时间索引排序,再来切片取值
#这里一定要注意,时间序列一定要排序
#否则这种取值方法会报错,无法取值
data.sort_index()["2015":"2015"]
另外一种做法是直接使用str的contains函数,因为需要2015年的数据,只需签约时间里面包含2015即可
data = data[data.cjshijian.str.contains("2015-")]
data
选取需要的特征
data = data[['cjdanjia','cjxiaoqu','cjlouceng']]
data
为了方便建模,所以需要对单价做处理,小区内容以空格分开,取得楼层的朝向
单价解决
data.cjdanjia = np.round((data.cjdanjia.str.replace("元/平","").\
astype('float'))/10000,2)
data.cjdanjia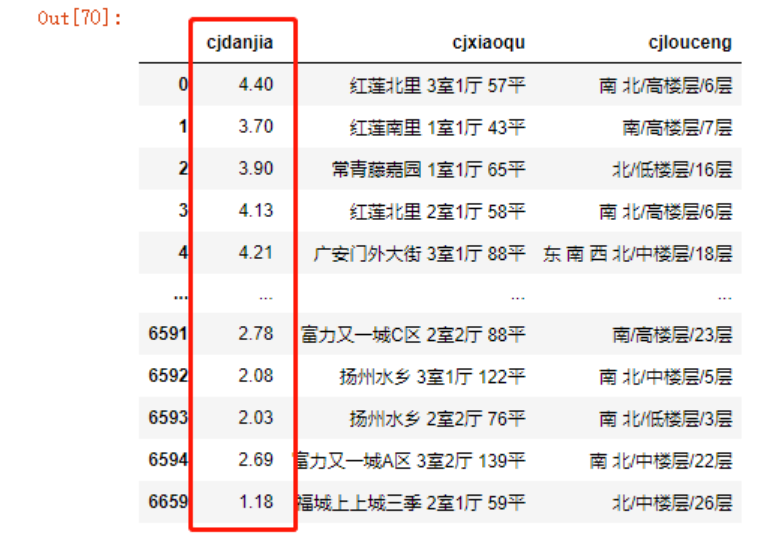
成交小区的内容清洗
#我们需要判断是不是所有的内容都是正确的
#即每一个列表的长度为3
data.cjxiaoqu.str.split(" ")
data.cjxiaoqu.str.split(" ").map(len)
np.sum(data.cjxiaoqu.str.split(" ").map(len) !=3)
可以看到所有的内容都符合要求,接下来对cjxiaoqu里面的三个内容进行分离,这里面运用的是Series的map函数
#错误的写法
# data.cjxiaoqu.str.split(" ")[0]
data.assign(xiaoqu=data.cjxiaoqu.map(lambda x:x.split(" ")[0]))
data.assign(huxing=data.cjxiaoqu.map(lambda x:x.split(" ")[1]))
data.assign(mianji=data.cjxiaoqu.map(lambda x:x.split(" ")[2]))
data.drop('cjxiaoqu',
axis=1,
inplace=True)
同的方法,处理楼层的问题
data = data.assign(chaoxiang=data.cjlouceng.map(lambda x:x.split("/")[0]))
data = data.assign(louceng=data.cjlouceng.map(lambda x:x.split("/")[1]))
取前15个小区
top15 = data.xiaoqu.value_counts()[:15]
top15
再利用布尔取值筛选出目标数据
top15.index

#注意,取得是top15.index
#top15是Series,默认取values
data.xiaoqu.isin(top15.index)
data[data.xiaoqu.isin(top15.index)]
同样,将面积处理一下
data.mianji = data.mianji.str.replace("平","").astype("float32")
data.head()
使用unique检查数据时,发现“暂无数据”,将其剔除
data.chaoxiang.unique()

sum(data.chaoxiang =="暂无数据")
data = data[data.chaoxiang !="暂无数据"]
到了这里就需要考虑一个问题了,因为我们后面要建立模型分析数据,中文数据明显是无法使用的,所以我们需要对变量的内容(例如楼层中的高、低等)进行编码,如果我们对低楼层标记1,对中楼层标记2,对高楼层标记3来代替可以吗?
不可以!因为对于机器来说,它会认为1+2=3,所以一个低+中楼层=高楼层,但这三个楼层根本没有这种线性关系!所以我们可以使用一种叫做one hot的编码。
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。表示分类变量最常用的方法就是使用one-hot编码(one-hot-encoding)或N取一编码(one-out-of-N encoding),也被称作虚拟变量(dummy variable)。虚拟变量背后的思想是将一个分类变量替换成一个或多个新特征,新特征取值为0和1。
测试代码如下
pd.get_dummies(data.louceng)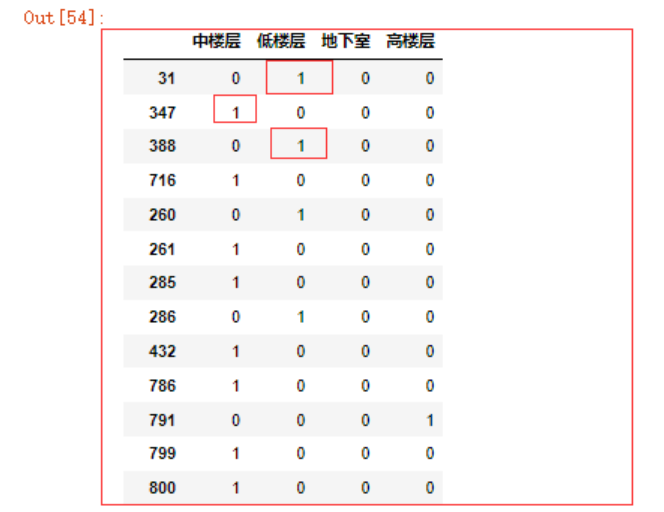
原本4个分类变量变成了4个特征,存在则为1,否则为0。
pd.merge(left=data,
right=pd.get_dummies(data.louceng),
left_index=True,
right_index=True)
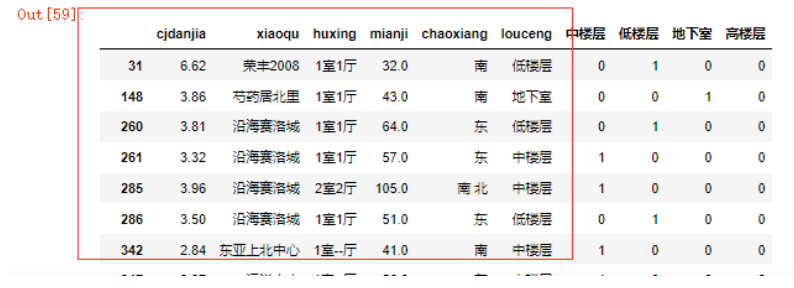
我们可以传入一个DataFrame到get_dummies函数中,一次性进行one hot编码。
pd.get_dummies(data=data[['xiaoqu','huxing','louceng']])
合并原始数据
data = pd.merge(left=data,
right=pd.get_dummies(data[['xiaoqu','huxing','louceng']]),
left_index=True,
right_index=True)
data=data.drop(data[['xiaoqu','huxing','louceng','cjlouceng']],
axis=1)
现在就是朝向没有进行编码,因为朝向的类别变量太多了,足足有27个
data.chaoxiang.unique()

我们还需要考虑一件事情,就是“南北”和“北南”理应是一样的,如果我们使用one hot编码,这个会生成两个特征,所以我们可以考虑使用自定义的方向编码。
例如,将朝向分为8个,“东南西北”+“东北 东南 西北 西南”即可囊括所有方向特征,这样不需要折腾成27个特征,也可以增加机器学习的效率。
实例代码:
# 测试
data['east']= data.chaoxiang.map(lambda x:x.split())
data['east']

data['east']= data.chaoxiang.map(lambda x:"东" in x.split())
data['east']
关于字符串的in判断,在python中,只有字符串完全匹配列表内的元素,才会被判断为真,例如,下例中,字符串“西”并不会被误判在列表中
>>> a = ['西南','东北']
>>> "西南" in a
True
>>> "西" in a
False
在chaoxiang的Series中,使用map传递一个匿名函数,判断朝向是否在列表中,返回一个布尔值。
再将布尔值转换为int类型。
data['east'] = data['east'].astype('int')
同理添加其它方向:
data['south']= data.chaoxiang.map(lambda x:"南" in x.split()).astype('int')
data['west']= data.chaoxiang.map(lambda x:"西" in x.split()).astype('int')
data['north']= data.chaoxiang.map(lambda x:"北" in x.split()).astype('int')
data['northeast']= data.chaoxiang.map(lambda x:"东北" in x.split() or "北东" in x.split()).astype('int')
data['southeast']= data.chaoxiang.map(lambda x:"东南" in x.split() or "南东" in x.split()).astype('int')
data['northwest']= data.chaoxiang.map(lambda x:"西北" in x.split() or "北西" in x.split()).astype('int')
data['southwest']= data.chaoxiang.map(lambda x:"西南" in x.split() or "南西" in x.split()).astype('int')
可以删除chaoyang列了
data.drop(data[['chaoxiang']],
axis=1,
inplace=True)
至此,数据的预处理就结束了。
建模及评估
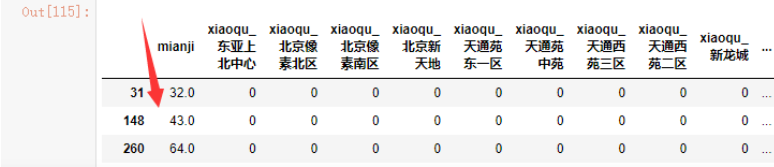
先来看下数据,除了第一列cjdanjia,其它字段均为特征。
这是一个监督学习问题,考虑使用线性回归模型来解决问题。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error制作模型X轴和Y轴
x = data[data.columns[1:]]
#或者使用这种写法,下面的更适合
#当要选取的值不好计算索引时
data[[x for x in data.columns if x !='cjdanjia']]
x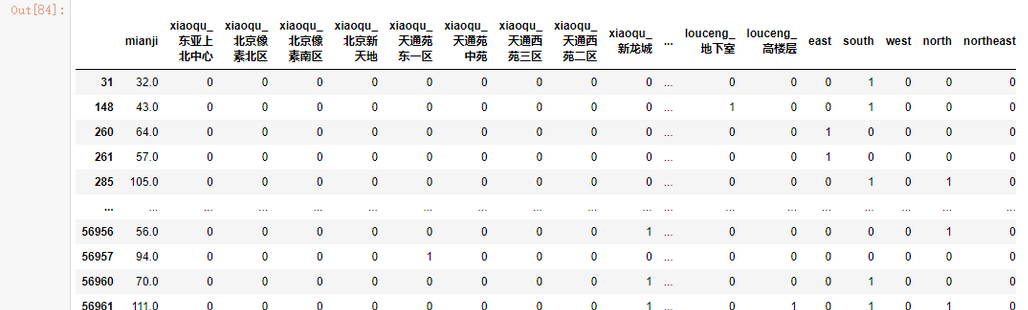
y = data[data.columns[0]]
y
打乱数据排序,抽取25%的数据用于验证结果
x_train,x_test,y_train,y_test = train_test_split(x,y)
model = LinearRegression()
model.fit(x_train,y_train)
model.coef_
#测试模型效果
mean_squared_error(y_test, model.predict(x_test))

制作第二个模型,减少一个特征,进行比较
#测试第二个模型
x2 = data[data.columns[2:]]
x2
y2 = data[data.columns[0]]
y2x2_train,x2_test,y2_train,y2_test = train_test_split(x2,y2)
model2 = LinearRegression()
model2.fit(x2_train,y2_train)mean_squared_error(y2_test, model.predict(x2_test))
可以看到第一个模型的误差更小。
模型的使用
现在可以使用一些真实的数据,来预测房子的单价了。
考虑生成一个Seires,索引为特征值(即除去需要预估的列名),np.zeros生成全0数据,修改索引的内容来生成one-hot编码。
index_name = data[[x for x in data.columns if x !='cjdanjia']]
index_name
data_test=pd.Series(np.zeros(shape=len((index_name.columns))),
index=index_name.columns)
填充数据,准备预测
data_test.mianji=90
data_test.louceng_中楼层=1
data_test.xiaoqu_远洋山水 =1
model.predict(data_test.values.reshape(1,-1))
