以下数据源来自于互联网公开的北京二手房成交数据,仅作个人学习使用。
目的:通过对2015年前三季度数据的分析,完成对房价涨幅超过10%的小区进行预判,并利用第4个季度的数据来验证模型的准确率。这是一个能与否的问题,所以是一个二分类问题,考虑使用逻辑回归来解决。
示例数据:
data.head()

提取需要的特征:
data= data[["cjzongjia","cjdanjia","cjxiaoqu","cjlouceng","cjshijian","bankuai","mendian","xingming","congyenianxian"]]
先将数据改成时间序列,方便取得2015年的数据,有三种思路,一种是利用str的contains函数,第二种考虑利用pandas读取csv文件的parse_dates参数,第三种就是常规方法,由于常规方法万金油,所以就从常规方法入手。
去除“签约时间”字符串,两种方法,一种是使用Seires的map函数中使用lambda匿名函数,另外一种pandas内置的str函数,当然pandas内置的函数更为高效。
# lambda
data.cjshijian.map(lambda x:x[5:])
data.cjshijian.map(lambda x:x.split(":")[1])
#推荐使用内置方法
#大数据量下较为高效
data.cjshijian.str.replace("签约时间:","")
data.cjshijian = data.cjshijian.str.replace("签约时间:","")
data.set_index(data.cjshijian, inplace=True)
data.index

data.index = pd.to_datetime(data.index)
data = data.sort_index()
data.index

取2015年的前三个季度和第四个季度的数据,注意使用data['2015']这种一个字符串去切片的方法目前是可以的,但是未来会被移除掉
data.loc['2015']
data['2015':'2015']
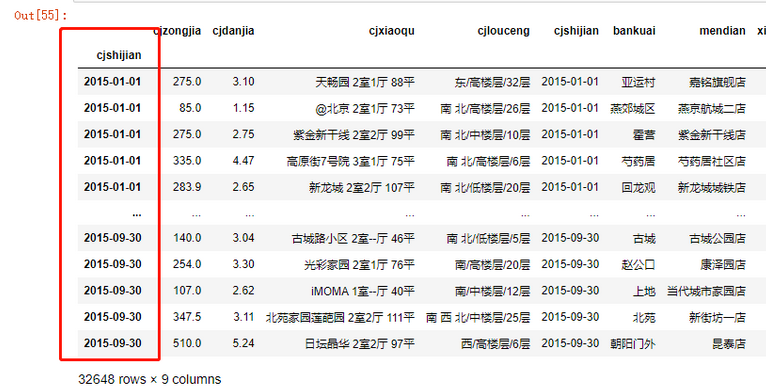
data3 = data['20150101':'20150930']
data3
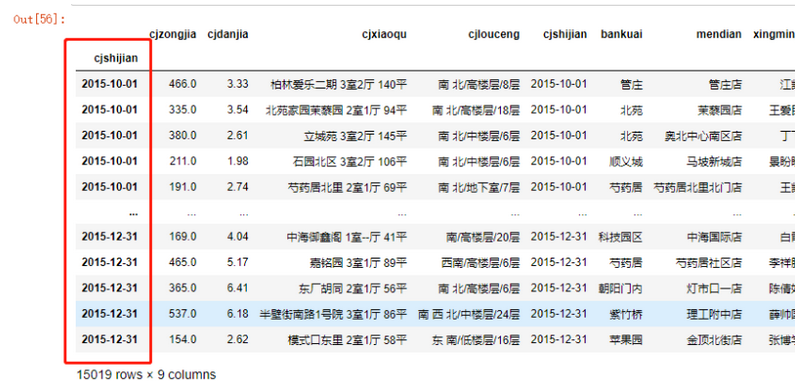
data4 = data['20151001':'2015']
data4
为了让模型具有代表性,所以将数据中成交数量低于5条的小区剔除掉,先看下cjxiaoqu的数据是否规整
(data3.cjxiaoqu.map(lambda x:len(x.split())) !=3).sum()
>1
说明有些变量内容长度不为3,将其先排除掉
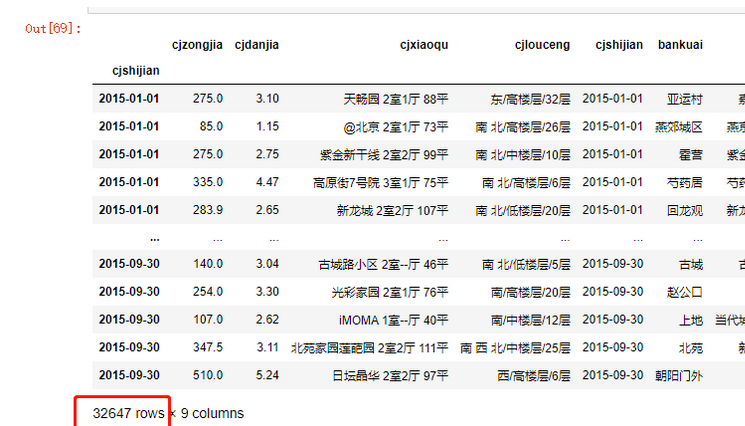
data3 = data3[data3.cjxiaoqu.map(lambda x:len(x.split())) ==3]
新增一个特征“小区”
data3 = data3.assign(xiaoqu =
data3.cjxiaoqu.map
(lambda x:x.split()[0])
)
records = data3['xiaoqu'].value_counts()
records

bigger5 =records[records>5]
bigger5

此时取出数据中成交记录大于5条的小区
data3=data3[data3.xiaoqu.isin(bigger5.index)]
由于需要计算第4个季度的房价涨幅,所以需要先算得前三个季度的cjdanjia的平均值,再利用(4季度单价平均值-3季度均值)/3季度均值获得涨幅:
# 前三个季度的cjdanjia的平均值
data3_mean = data3.groupby('xiaoqu')['cjdanjia'].mean()
data3_mean

对于第4季度的数据data4,如果我们也按照之前的方法进行处理
data4 = data4[data4.cjxiaoqu.map(lambda x:len(x.split())) ==3]
data4 = data4.assign(xiaoqu =
data4.cjxiaoqu.map
(lambda x:x.split()[0])
)
records_2 = data4['xiaoqu'].value_counts()
bigger55 =records_2[records_2>5]
data4 = data4[data4.xiaoqu.isin(bigger55.index)]
data4
data4_mean = data4.groupby('xiaoqu')['cjdanjia'].mean()
data4_mean

但是,存在一个问题,就是前三季度成交量大于5条的小区未必在第四季度成交量也大于5条,来看下例子:
(data4_mean -data3_mean)/data3_mean
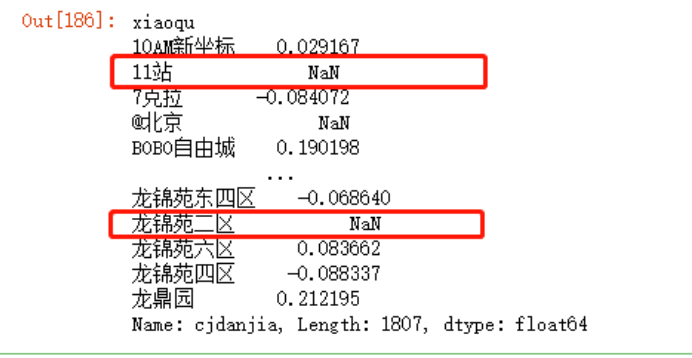
就比如其中的“龙锦苑二区”,在第4个季度就不存在交易
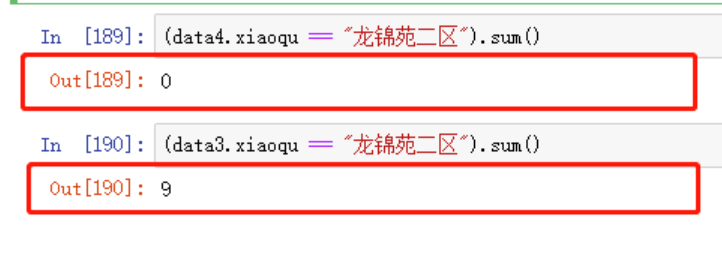
所以在计算成交记录大于5条时,我们应该选择前三个季度的小区records
#前面的代码几乎一样
data4 = data4[data4.cjxiaoqu.map(lambda x:len(x.split())) ==3]
data4 = data4.assign(xiaoqu =
data4.cjxiaoqu.map
(lambda x:x.split()[0])
)
#前三个季度成交量大于5条
records = data3['xiaoqu'].value_counts()
bigger5 =records[records>5]
data4 = data4[data4.xiaoqu.isin(bigger5.index)]
data4
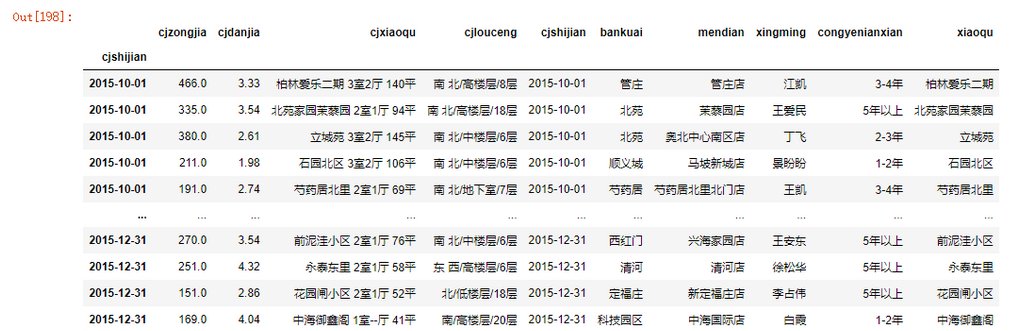
data4_mean = data4.groupby('xiaoqu')['cjdanjia'].mean()
increase = (data4_mean -data3_mean)/data3_mean
increase
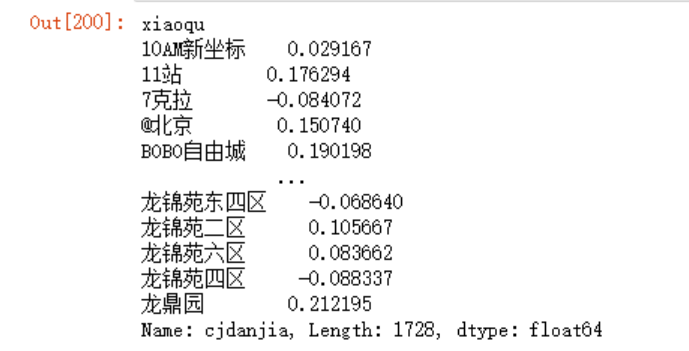
我们现在想要获取涨幅在10%以上的小区,并将其设置为目标值,建立相关特征,首先将increase转化成DataFrame,方法很多,以下两种方法均可
increase.to_frame()
pd.DataFrame(increase)
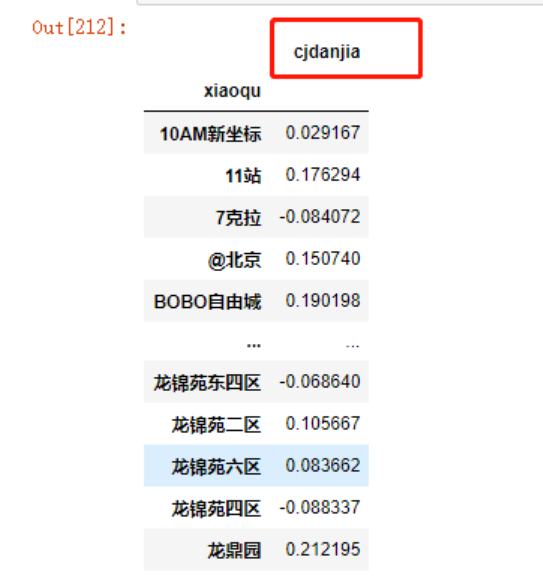
increase = increase.dropna()
increase = increase.to_frame()
可以看到这个列名不对,直接修改,注意,这种方法传入的必须的是一个完整列名的列表
increase.columns = ['up_pct']
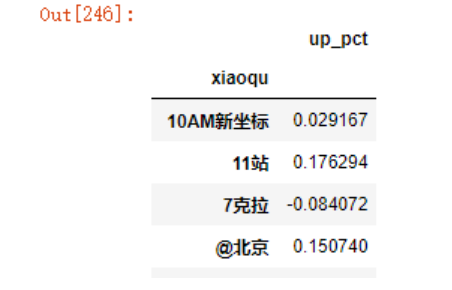
现在,开始为这个DataFrame增加目标,即涨幅是否超过10%
increase.up_pct> 0.1

返回的布尔值我们可以使用astype方法将其转为数值类型
increase = increase.assign(ten=
(increase.up_pct> 0.1).astype("int"))
increase

现在目标有了,可以开始选取特征了,例如成交的套数,小区的单价(似乎单价起点低的涨幅更容易突破),房子的总价等
data3.xiaoqu.value_counts().to_frame()

#合并到新的DF中increase
#但是列名应以新的DF为准
increase = pd.merge(increase,
data3.xiaoqu.value_counts().to_frame(),
left_index=True,
right_index=True,
how='left')
increase
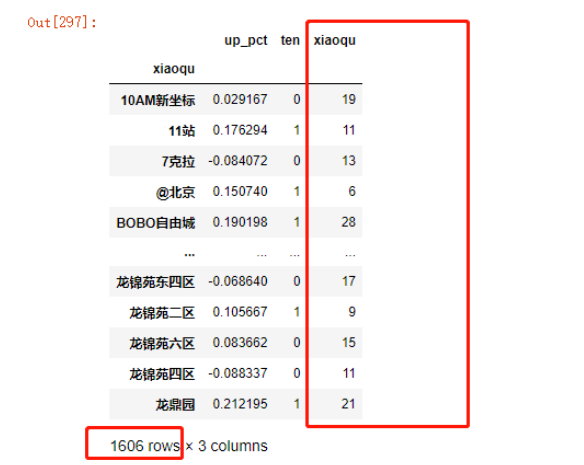
使用rename函数更改下列名:
increase.rename(columns=
{'xiaoqu':'taoshu'},
inplace=True)
increase.drop(columns='up_pct',inplace=True)
increase

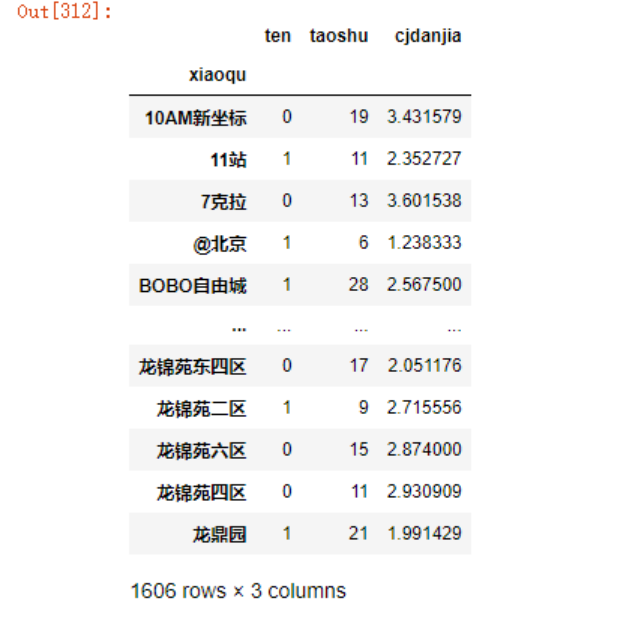
同样,获取单价特征
data3.groupby('xiaoqu')['cjdanjia'].mean()

increase = pd.merge(increase,
data3.groupby('xiaoqu')['cjdanjia'].mean().to_frame(),
left_index=True,
right_index=True,
how='left')
increase
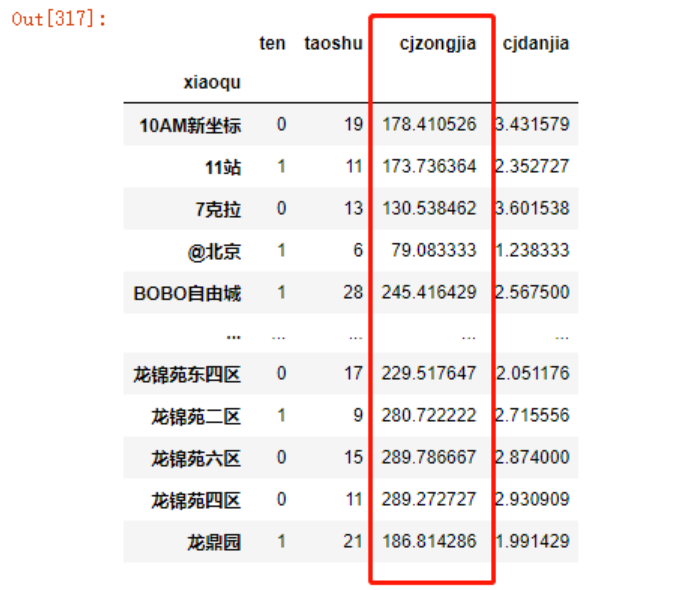
同样,获取房价特征
data3.groupby('xiaoqu')['cjzongjia'].mean()

increase = pd.merge(increase,
data3.groupby('xiaoqu')['cjzongjia'].mean().to_frame(),
left_index=True,
right_index=True,
how='left')
increase
开始准备数据建模,需要注意的是我们的训练数据应该统一选择前三季度的数据,下面的例子中选择的是70%。
#permutation为每条数据
#都分配了一个乱序索引
index = np.random.permutation(len(increase))
index
#建立70%训练数据
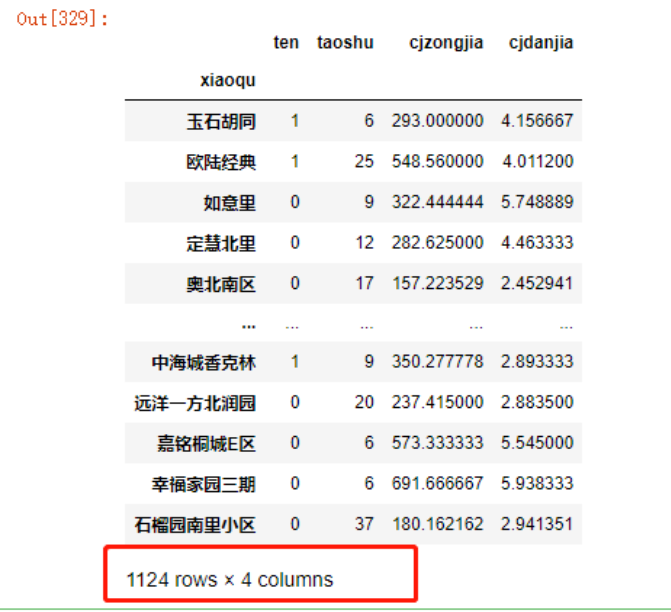
data_train = increase.iloc[index[:int(len(increase)*0.7)]]
data_train
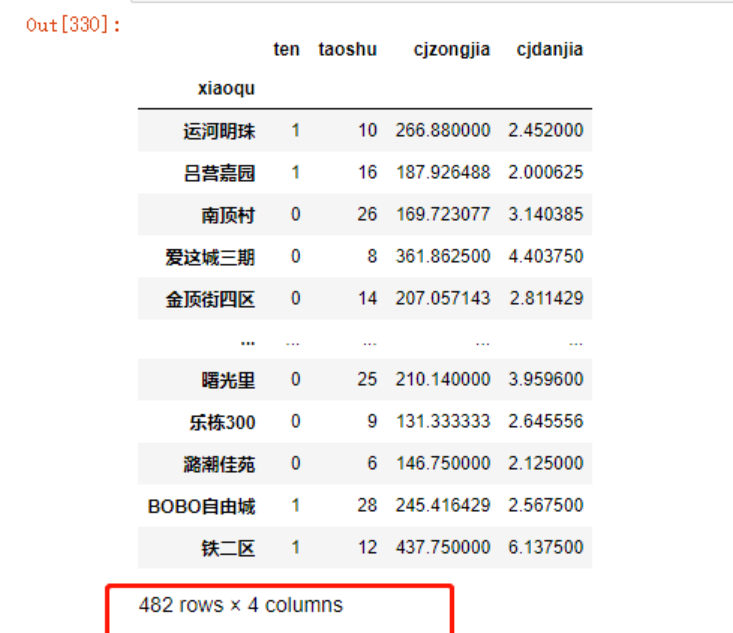
data_test = increase.iloc[index[int(len(increase)*0.7):]]
data_test
x_train,y_train = data_train[list(x for x in data_train.columns if x != 'ten')],\
data_train.ten
x_test,y_test = data_test[list(x for x in data_test.columns if x != 'ten')],\
data_test.ten
或者直接使用sklearn.model_selection里面的快捷函数
x_train,x_test,y_train,y_test = \
train_test_split(increase[list(x for x in increase.columns if x != 'ten')],
increase.ten,
test_size=0.3)
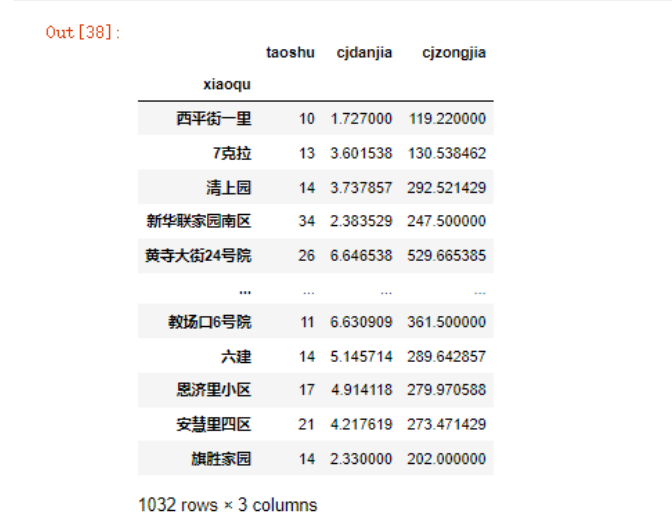
x_train
建立模型
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(x_train, y_train)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, model.predict(x_test))
# model.score(x_test,y_test)
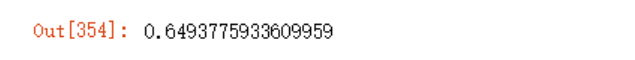
可以看到准确率只有64%。
我们也可以再次新增特征,例如:各小区成交的经纪人人数:
data3.groupby('xiaoqu')['xingming'].unique().map(len)

increase = pd.merge(increase,
data3.groupby('xiaoqu')['xingming'].unique().map(len).to_frame(),
left_index=True,
right_index=True,
how='left')
increase
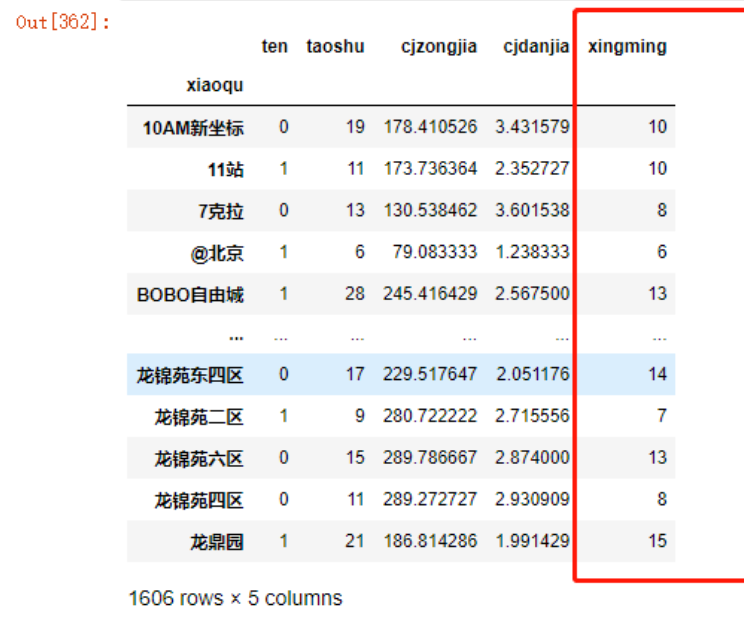
其它的流程重新再走一遍:
index = np.random.permutation(len(increase))
data_train = increase.iloc[index[:int(len(increase)*0.7)]]
data_test = increase.iloc[index[int(len(increase)*0.7):]]
x_train,y_train = data_train[list(x for x in data_train.columns if x != 'ten')],\
data_train.ten
x_test,y_test = data_test[list(x for x in data_test.columns if x != 'ten')],\
data_test.ten
model = LogisticRegression()
model.fit(x_train, y_train)
accuracy_score(y_test, model.predict(x_test))
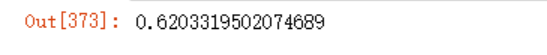
可以看到,准确率更低了,这也说明特征并非越多越好。