随机森林算法可用于分类,也可用于回归任务。
随机森林采用集合算法(bagging),利用统计学采样原理,训练出成千上百个不同的算法模型。当需要预测时,使用这些模型分别对样本进行预测,然后采取少数服从多数的原则,决定样本的类别。
随机森林算法在每次训练时,不仅仅只是抽取部分数据(有放回的),对于特征也是随机抽取部分进行训练,这样生成的模型会非常多。
算法原理:
- 采样样本(放回采样)
- 采样特征
- 构建决策树
- 重复t次,构建出t棵决策树
- 综合多棵决策树的预测结果,作为随机森林的预测结果。(回归问题:平均值;分类问题:少数服从多数)
关于这个放回采样,以下内容摘录江户川柯壮的博客:
如果我们有个大小为N的样本,我们希望从中得到m个大小为N的样本用来训练。那么我们可以这样做:首先,在N个样本里随机抽出一个样本x1,然后记下来,放回去,再抽出一个x2,… ,这样重复N次,即可得到N的新样本,这个新样本里可能有重复的。重复m次,就得到了m个这样的样本。实际上就是一个有放回的随机抽样问题。每一个样本在每一次抽的时候有同样的概率(1/N)被抽中。
关于抽取部分特征的原因在于,如果所有特征都在一起,很多时候影响特别大的特征会把影响较小的特征完全覆盖掉,导致过拟合,而抽样特征则确保了所有特征都会对预测结果产生影响。
该算法还可以量化特征的重要性,原理在于随机森林会通过察看使用特征减少了森林中所有树多少的不纯度,以此来衡量特征。
from sklearn.ensemble import RandomForestClassifier
Init signature:
RandomForestClassifier(
n_estimators=100,
*,
criterion='gini',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0.0,
max_samples=None,
)
几个常用的参数:
- n_estimators:森林里(决策)树的数目。
- max_features:它表示随机森林在单个树中可拥有的特征最大数量。
- min_sample_leaf:叶节点最小样本数
- n_jobs:表示允许使用处理器的数量。若值为1,则只能使用一个处理器。值为-1则表示没有限制。
以上一篇文章的泰坦尼克号获救数据为例。
前面的处理代码都一样:
data_train = df[[x for x in df.columns if x !='Survived']]
data_test = df['Survived']
x_train,x_test,y_train,y_test = train_test_split(data_train, data_test)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100,
n_jobs=4)
关于快速将Series数据扁平化成ndarray的快捷方式:
y_train

y_train.ravel()

# model.fit(x_train,y_train.ravel())
model.fit(x_train,y_train)
model.score(x_test,y_test.ravel())
![]()
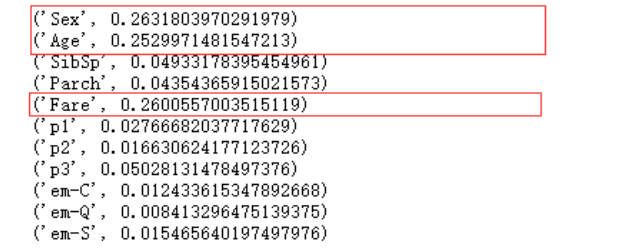
可以利用feature_importances_属性很便捷的查看各特征的重要性
model.feature_importances_

利用python的zip函数看的更清楚一点
for x in zip(data_train.columns.values, model.feature_importances_):
print(x)
如果想要使用模型,下面两种方法都可以:
model.predict([x_test.iloc[0].ravel()])
model.predict(x_test.iloc[0].values.reshape(1,-1))
我们照样还是可以使用GridSearchCV的交叉验证:
from sklearn.model_selection import GridSearchCV
numberTree = range(80,200)
model = GridSearchCV(estimator=RandomForestClassifier(),
param_grid={"n_estimators":numberTree},
cv=5)
注意上面传入的estimator必须是实例instance,而非类class。
model.fit(x_train,y_train)
model.score(x_test,y_test.ravel())
计算量比较大,慢慢等着就行。

照例,使用GridSearchCV的best_params_和best_score_ 属性取出最佳参数和最佳分数。
model.best_params_, model.best_score_

参考:https://blog.csdn.net/edogawachia/article/details/79357844
https://www.cnblogs.com/amberdata/p/7203632.html