最近学了一些数据分析、机器学习的基础知识,刚好朋友有一个需求,希望能对两份数据进行清洗,把里面的缺失值按照条件替换成平均值,数据清洗步骤如下:
- 对于每一列观察值,按照SUB和CON将其中的空缺值(.)、零值(0)替换成其他合适的值(一般用每个被试SUB在各个条件CON下的平均数)
- 删除位于平均数(SUB在各个条件下的平均数)三个标准差之外的离群值,后更改为“条件值如FFD 大于平均数+3*标准差,或 小于平均数-3*标准差”的离群值
- 生成数据分布趋势图(QQ图或者箱型图都可以)
该篇文章展示的部分数据已经征得朋友的同意。
首先导入两个科学计算库
import pandas as pd
import numpy as np
看下第一份数据的情况,因为存在很多省略号,所以在读取的时候就直接使用na_values参数将其输出为空值了(上面题中其实为0的值也应当视为空缺值,但是read_excel函数似乎有些问题,所以之后我再来处理内容为0的数据)
df1 = pd.read_excel('mx/DEAF_RAW_0914.xlsx',na_values='.')
df1.head()
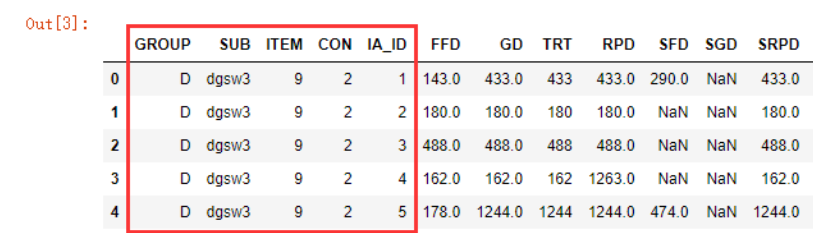
这里面前5个字段,我们或许可以将其视为自变量。
GROUP:组别,共有2个组别,D代表聋人Deaf组,H代表听人Hearing组;SUB:每一个参与实验的被试的编号,代表每一个个体;ITEM:每一个实验句的编号,每个志愿者在正式实验中都会看到96个句子,每个句子都有一个编号,相当于一个实验刺激;IA_ID:兴趣区编号,将一个句子按照词划分成一个个区域,每个区域对应着一个编号,1-5对应这句子从句首到句尾每一个我们感兴趣的部区域;CON:条件编号,对实验句进行不同的操纵,形成4种不同的条件,对应着1、2、3、4这几个数字,每个item都只有一个的condition(4选1)。
我们再来看下各字段的空缺情况
df1.info()
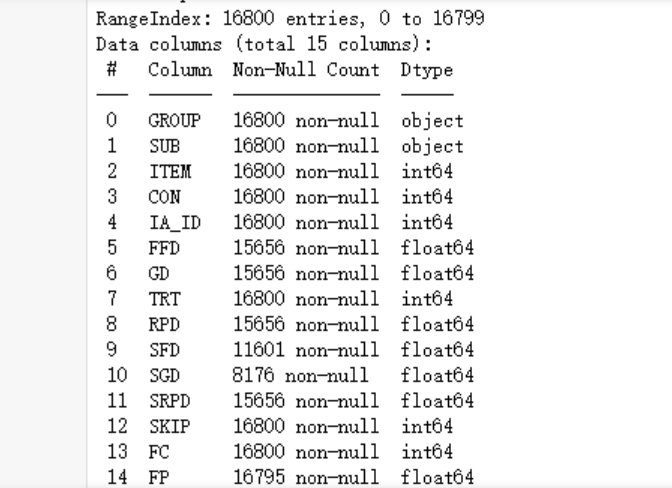
可以看到,合计15个字段,一共存在16800行数据,缺失值还是很有一些的,接下来我们加载第二份数据
df2 = pd.read_excel('mx/HEARING_RAW_0914.xlsx',na_values='.')
df2.head()

df2.info()

可以看到这份数据的字段和数据明显比第一份多,存在24480行数据,存在18列数据,而且居然存在两个Unnamed字段,所以我们先使用dropna函数将其中一列完全为空的数据清洗掉并覆盖原始数据
df2 = pd.read_excel('mx/HEARING_RAW_0914.xlsx',na_values='.')
df2.dropna(axis='columns', how='all', inplace=True)
由于Reading字段并无作用,所以我们稍作处理如下:
df3 = df2[[x for x in df2.columns.values if x !='Reading']]
df3 = df3.iloc[:,:-1]
上面这段代码将第二份数据中不等于Reading的所有列都取出来,并使用花式切片去除了最后的一列(Unnamed),这样我们就得到了一份字段完全和第一份数据相同的数据df3
接下来将两份数据进行合并,可参考pandas合并数据集,concat是一个很好的函数:
df = pd.concat([df1,df3])
df.info()

接下来就可以考虑将所有为0的数值填充为缺失值了(备注:之前我确实在read_csv函数中使用na_values参数替换过数值0,不知道read_excel中为什么会出现这个bug,待查),关注一下上面我圈起来的红色字段
df.replace([0], np.nan,inplace=True)
df.info()
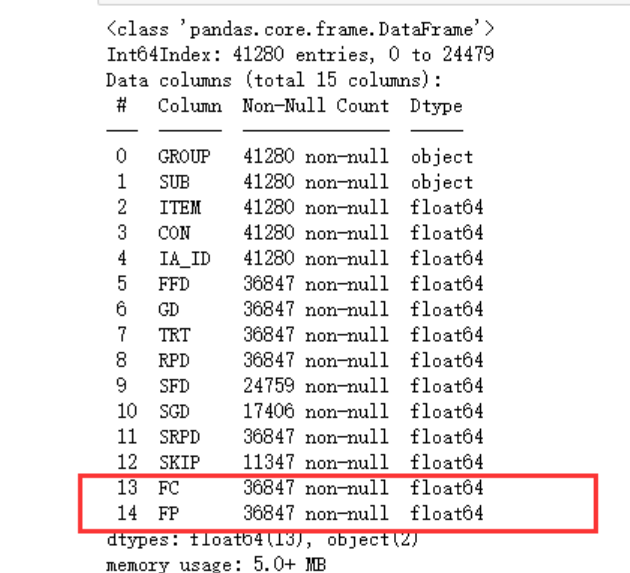
可以看到数据确实增加了很多缺失值。
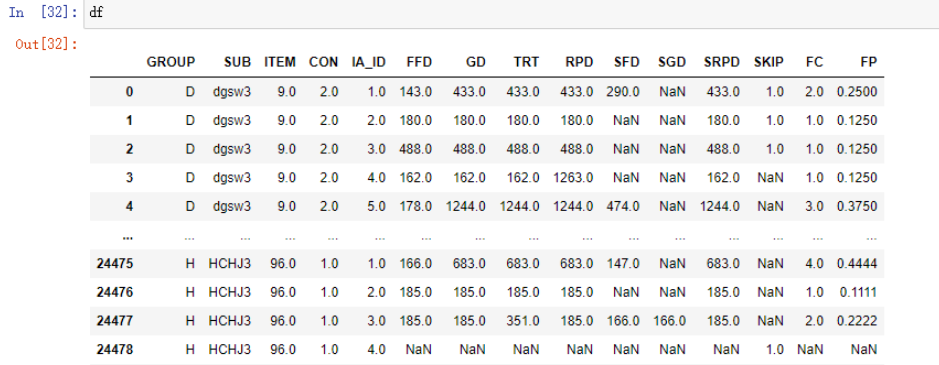
合并之后的数据如下:
接下来就是聚合数据的内容了,代码如下
means_columns = df.groupby(['SUB','CON','IA_ID'])[[x for x in df.columns if x not in ['ITEM','CON','IA_ID']]].mean()
means_columns
首先按照'SUB','CON','IA_ID'三个类别进行了聚合,得到一个DataFrameGroupBy实例,再对其取值,除了'ITEM','CON','IA_ID'三个值不需要求均值,其它的字段统一按照聚合的类别求取均值
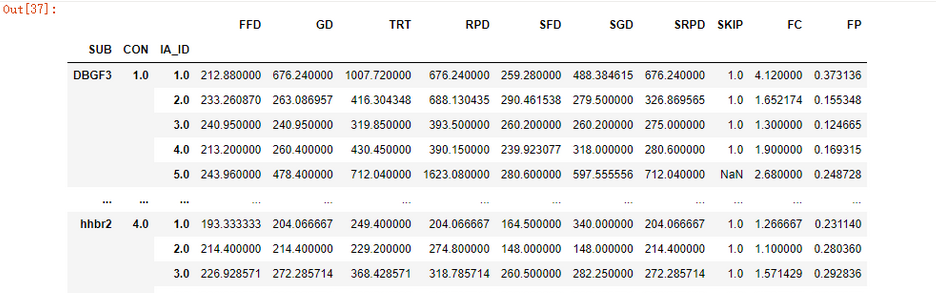
得到了一个1720行均值数据,这第一条数据的含义是在SUB为DBGF3,CON为1,IA_ID为1时,FFD均值为212.880000,以此类推。
此时,我的思路是想将其与原始数据合并,然后对原始数据中的缺失值进行旁值填充,具体操作如下:
mean_data = pd.merge(df,pd.DataFrame(means_columns), on=['SUB','CON','IA_ID'],suffixes=('','_mean'))
mean_data
首先将原数据和新生成的均值数据以'SUB','CON','IA_ID'三个字段进行合并,新生成的means_columns数据相同字段以_mean为后缀,得到一个41280 rows × 25 columns的矩阵
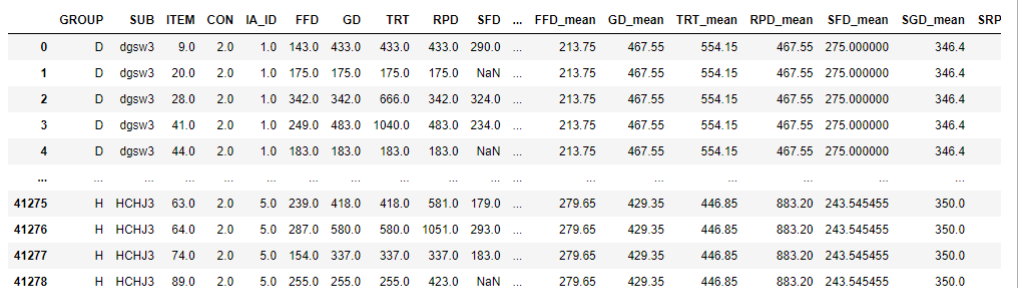
mean_data.sort_index(axis="columns").fillna(method='bfill', axis=1)
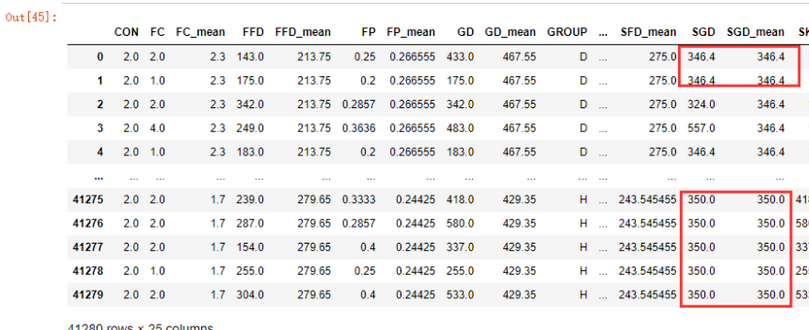
上面的代码首先将数据以列名进行了排序,这样相同前缀的列名就会排列到一起,再利用fillna函数对每一列中的缺失值进行后填充,为什么可以直接使用fillna函数进行填充呢?因为在前面的数据分析中,我已经知道了数据的几个关键自变量不存在缺失值:
将不需要的字段删除掉(也可不删除,留待第二步)
mean_data.drop(columns=[x for x in mean_data.columns if 'mean' in x], inplace=True)
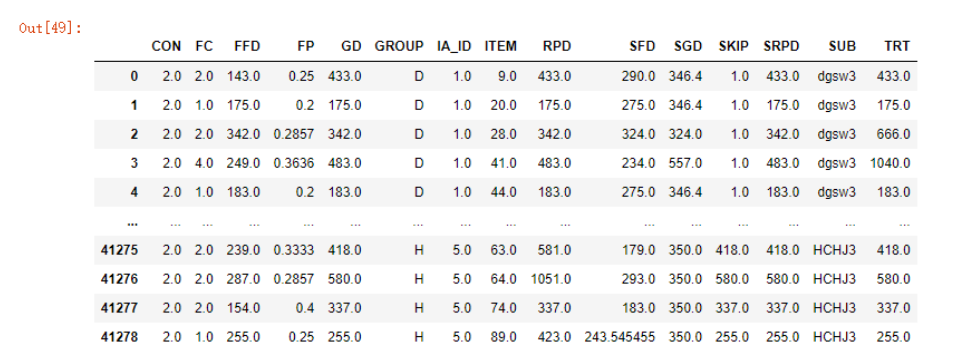
清洗数据的第一个步骤就完成了。
第二个步骤其实也是一样的方法,我们需要先获得目标的标准差std:
std_columns = df.groupby(['SUB','CON','IA_ID'])[[x for x in df.columns if x not in ['ITEM','CON','IA_ID']]].std()
std_columns
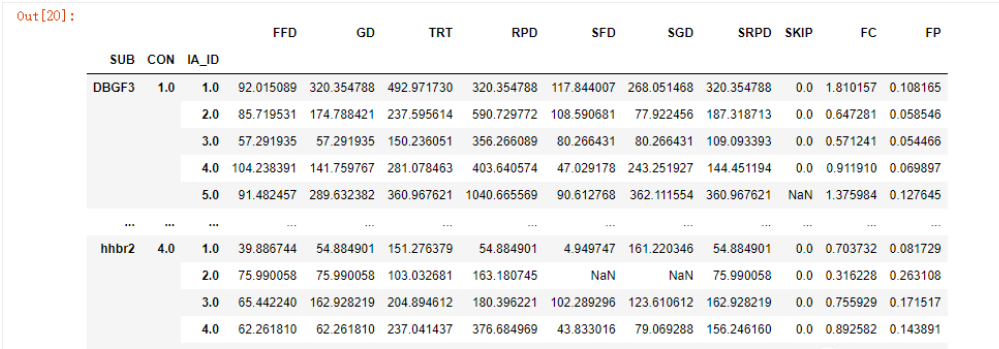
然后进行合并,排序
std_data = pd.merge(mean_data,pd.DataFrame(std_columns), on= ['SUB','CON','IA_ID'],suffixes=('','_std')).sort_index(axis="columns")
std_data
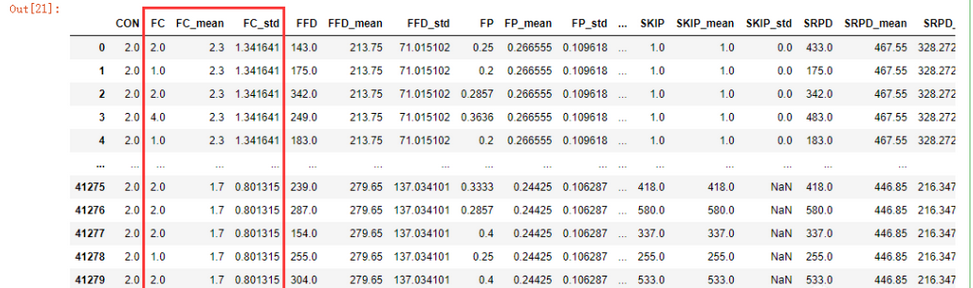
现在就需要计算“大于平均数+3*标准差,或小于平均数-3*标准差”,可以一个个来计算,但是为了简便起见,我还是写了一个函数:
def processStd(data,*args,std_suffix='_std',mean_suffix = "_mean"):
_ = []
for x in data.columns:
if x not in args and std_suffix not in x and mean_suffix not in x:
_.append(x)
print(_)
for i in _:
condi1 = data[i+ mean_suffix] + 3*data[i+std_suffix]
condi2 = data[i+ mean_suffix] - 3*data[i+std_suffix]
new_column = pd.DataFrame( np.where( (data[i] > condi1) | (data[i] < condi2), True, False))
data[i+"_TriStd"] = new_column
processStd(std_data,'CON','SUB','IA_ID','GROUP','ITEM')
这个函数接受一个dataframe,然后任意数量的不想要的参数,在上面,我不需要'CON','SUB','IA_ID','GROUP','ITEM'这几个字段参加计算,同时标准差列_std和平均数列_mean也不需要参加计算,最后利用numpy的where函数筛选出符合的数据并设置为True,处理完成之后
std_data.sort_index(axis='columns', inplace=True)
std_data
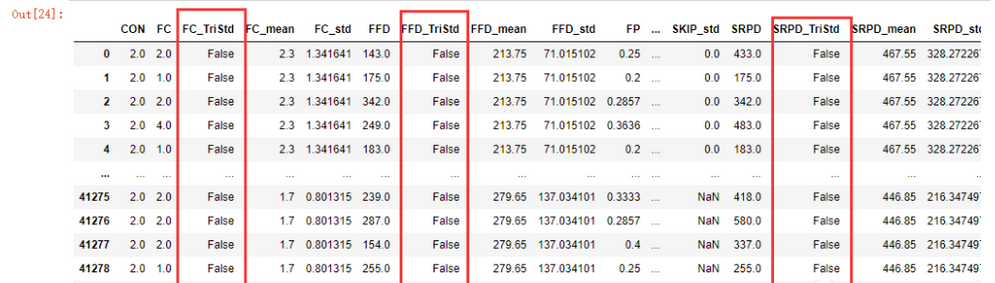
我们现在把不需要的字段例如标准差、平均值列清理一下
std_data.drop(columns=[x for x in std_data.columns if '_mean' in x or '_std' in x], inplace=True)
std_data
再来考虑剔除不符合标准的行,当然最不用动脑的方法肯定是一个个写过去,例如
std_data[std_data['FC_TriStd'] !=True]
这种方法肯定可以,但是未免过于繁琐,由于需要判断的字段里面都存在TriStd字符串,所以可以考虑利用函数来解决
def extract_data(data, suffix='_TriStd'):
_ = [x for x in std_data.columns if suffix in x]
for i in _:
data = data[data[i] != True]
return data
extract_data(std_data).set_index(['SUB','CON','IA_ID'], append=True).to_excel('demo_6.xlsx')
# output = extract_data(std_data)
# output.drop(columns=[x for x in output.columns if 'TriStd' in x], inplace=True)
#output.set_index(['SUB','CON','IA_ID'],append=True).to_excel('full_version.xlsx')
第二项问题解决。
尽管已经做了很多优化,可以在后续复用,但在我看来,这种方法并不简洁,python应该还有更好的处理方法,留待后续再补记录。