概念:利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
应用:例如抖音APP,平时美女看多了,给你推荐的都是美女小视频;又例如今日头条,你喜欢浏览军事的新闻,给你推荐的都是军事新闻等等。
算法分为以用户为基础(User-based)的协同过滤和以项目为基础(Item-based)的协同过滤。
在了解这个算法之前,需要了解一个概念:余弦相似度。
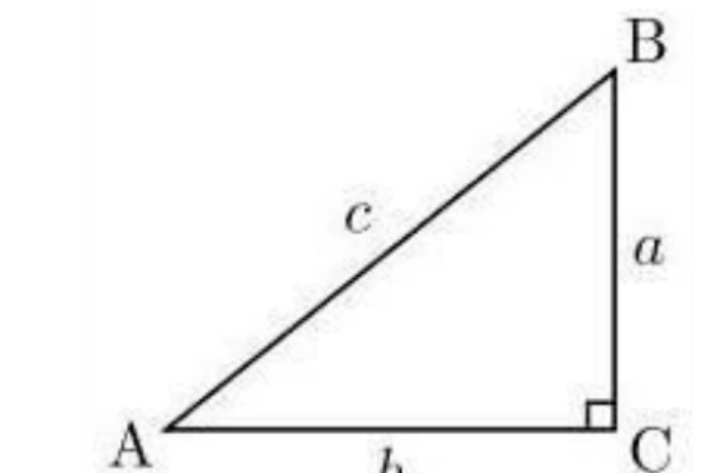
我们知道,在直角三角形,∠C=90°(如图所示),∠A的余弦是它的邻边比三角形的斜边,即cosA=b/c,也可写为cosa=AC/AB。余弦值范围为[-1,1]。
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度的取值范围也是[-1,1],两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。
可以看到当余弦相似度越大,则二者更贴近,更为相似。
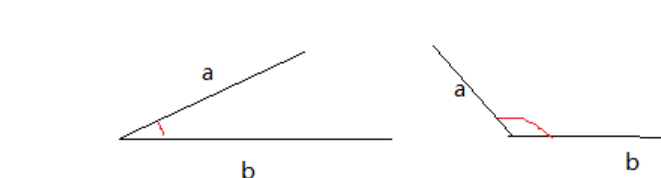
关于余弦相似度的计算公式,目前还看不懂,但是在sklearn中有相关的工具cosine_similarity可以使用,cosine_similarity位于metrics的孙子级(之前使用过的accuracy_score、mean_squared_error都位于该库下)。
通过一个小例子来解释,示例中,ABCD分别代表顾客对7件商品abcdefg的评分:
from numpy import nan as NA
data = pd.DataFrame([
[4,NA,2,NA],
[NA,4,NA,5],
[5,NA,2,NA],
[3,4,NA,3],
[5,NA,1,NA],
[NA,5,NA,5],
[NA,NA,NA,4]
],
index = list('abcdefg'),
columns=list('ABCD')
)
df = data.T
df
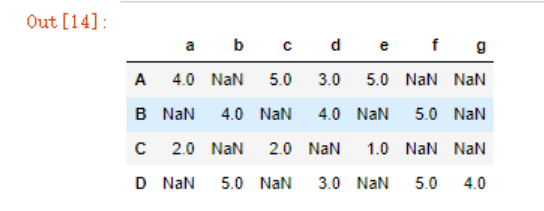
目标:
- 我们要寻找与A顾客最相似的顾客
- 预测A顾客对b商品的评分,以确定是否要向A推荐b商品
#导入
from sklearn.metrics.pairwise import cosine_similarity
计算B与A的相似度,先试下直接将AB两条Series丢进去:
simAB = cosine_similarity(df.iloc[0], df.iloc[1])

提示需要一个2D数组,可以使用numpy函数修改一下
df.iloc[1].values.reshape(1,-1)

simAB = cosine_similarity(df.iloc[0].values.reshape(1,-1),
df.iloc[1].values.reshape(1,-1))
再次报错,NaN需要更改

再次将NaN值填充为0试试
simAB = cosine_similarity(df.iloc[0].fillna(0).values.reshape(1,-1),
df.iloc[1].fillna(0).values.reshape(1,-1))
这一次没有报告异常,我们可以看下返回的相似度
simAC = cosine_similarity(df.iloc[0].fillna(0).values.reshape(1,-1),
df.iloc[2].fillna(0).values.reshape(1,-1))
simAD = cosine_similarity(df.iloc[0].fillna(0).values.reshape(1,-1),
df.iloc[3].fillna(0).values.reshape(1,-1))
simAB,simAC,simAD

上面最明显的莫过于用户A和用户C之间有88%的相似度,我们再来看下原始数据
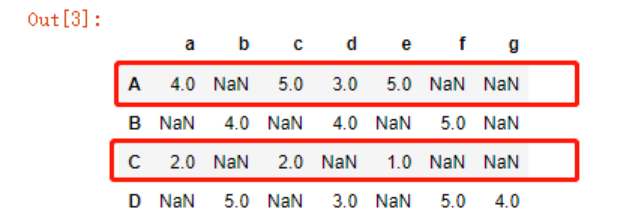
这明显不符合实际情况啊,凡是用户A喜欢的商品,用户C就给了低分,这哪里相似,分明相左才对!
但如果我们把这个数据稍微改动下就能够理解了,上面在使用cosine_similarity函数时,由于输入不能包含NaN,所以我们对NaN填充了0,所以cosine_similarity函数中接受的输入其实是下方这个样本:
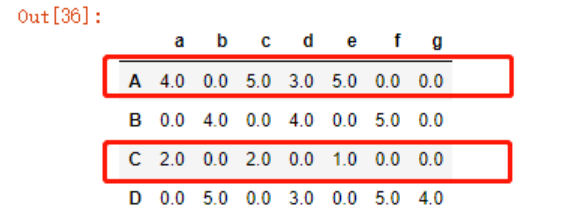
从这张图中,我们可以看到,用户A、C均给了商品bfg0分(在cosine_similarity函数中,0并非中立值),所以被判定为88%的相似度,因此我们的输入需要改变!
去中心化
去中心化,在上面的例子中,就是把所有的数值减去其(这一行的)均值。
好处?
首先,在减去平均值之后,再对NaN进行填充0,则0变成了一个中性值;其次,有些人买东西之后就是这东西再完美,他也不会给满分(习惯给低分);而有些人,习惯给高分,减去其给商品评分的平均值之后,就让用户之间的评分变得更为客观一些了。
df.mean(axis=1)
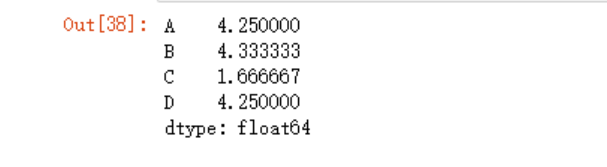
df.apply(lambda x: (x-df.mean(axis=1)) )
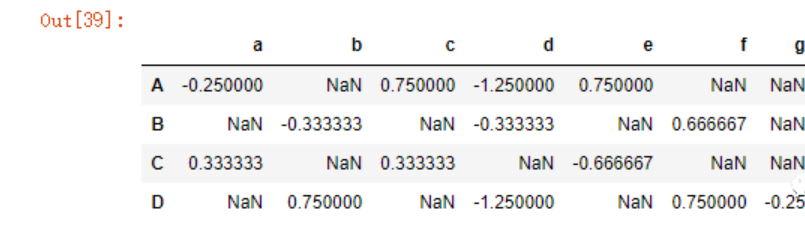
#去中心化之后再进行比较
#x指的就是DF中的每一行
df_center = df.apply(lambda x: x-x.mean(),axis=1)
df_center
simAB = cosine_similarity(df_center.iloc[0].fillna(0).values.reshape(1,-1),
df_center.iloc[1].fillna(0).values.reshape(1,-1))
simAC = cosine_similarity(df_center.iloc[0].fillna(0).values.reshape(1,-1),
df_center.iloc[2].fillna(0).values.reshape(1,-1))
simAD = cosine_similarity(df_center.iloc[0].fillna(0).values.reshape(1,-1),
df_center.iloc[3].fillna(0).values.reshape(1,-1))
simAB,simAC,simAD

可以看到,此时AC用户之间的余弦相似度变为负值,用户D与A用户最为相似。
第一个问题已经解决,第二个问题,预测用户A对商品b的评价。
首先,从上面我们知道用户A、B、D是有相似性的,且BD均对商品b做了评价,计算用户A的评分公式应该为:
(B的相似度*B的评分 + D的相似度*D的评分)/BD的权重
这里BD的权重其实就是B、D与A的相似度。
(simAB*df.loc['B','b'] + simAD*df.loc['D','b'])/ (simAB + simAD)

可以看到,用户A可能会对商品b给出4.6的高分。
以项目为基础的协同过滤
优于基于用户的协同过滤。
新建测试数据,用户U1-U5对商品0-4的评分
data = pd.DataFrame({
'U1':[2,None,1,None,3],
'U2':[None,3,None,4,None],
'U3':[4,None,5,4,None],
'U4':[None,3,None,4,None],
'U5':[5,None,4,None,5]},
index = ["goods"+str(x) for x in range(1,6)],
)
data
目标:预测U3用户对goods5的评分。
#同样的,先进行中心化
df_center = data.apply(lambda x:x-x.mean(),
axis=1)
df_center
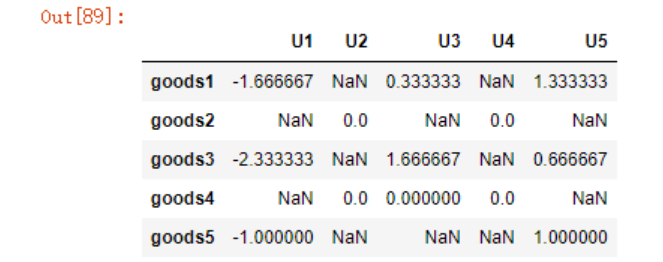
我们可以与上面一样,一步步计算出结果
#先计算物品的相似度
#goods5与goods1
gu1 = cosine_similarity(df_center.iloc[4].fillna(0).values.reshape(1,-1),
df_center.iloc[0].fillna(0).values.reshape(1,-1))
gu1
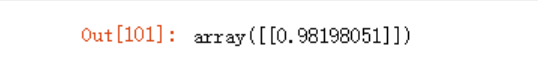
gu2 = cosine_similarity(df_center.iloc[4].fillna(0).values.reshape(1,-1),
df_center.iloc[1].fillna(0).values.reshape(1,-1))
gu2

gu3 = cosine_similarity(df_center.iloc[4].fillna(0).values.reshape(1,-1),
df_center.iloc[2].fillna(0).values.reshape(1,-1))
gu3

gu4 = cosine_similarity(df_center.iloc[4].fillna(0).values.reshape(1,-1),
df_center.iloc[3].fillna(0).values.reshape(1,-1))
gu4
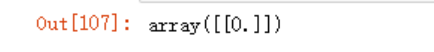
#可以看到项目5和1、3具有相似性
#而U3用户对1和3是有评分的
#同样的道理计算得分
(gu1*data.loc['goods1','U3'] + gu3*data.loc['goods3','U3'])/(gu1 + gu3)
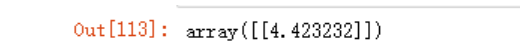
这种方法在数据比较少时可以慢慢算,但数据量过大时,就很麻烦了。
规范的做法,先写一个函数来解决相似度问题。
_ = []
for i in range(len(df_center)):
goods = cosine_similarity(df_center.iloc[4].fillna(0).values.reshape(1,-1),
df_center.iloc[i].fillna(0).values.reshape(1,-1))
_.append(goods[0][0])
_
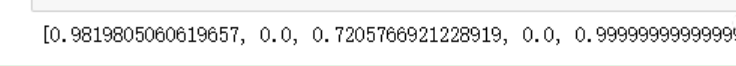
#重新组合成DF
rating = pd.DataFrame({
'rate':_,
'UU':data.U3
})
rating
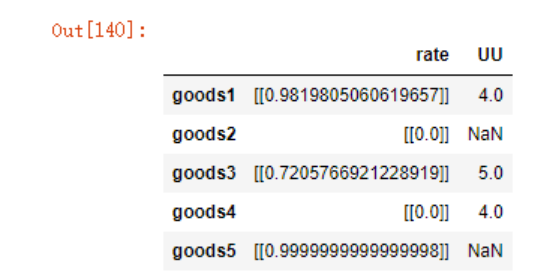
rating.dropna(inplace=True)
rating
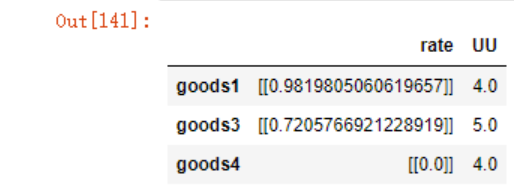
rating.rate = rating.rate.map(lambda x:x[0][0])
rating
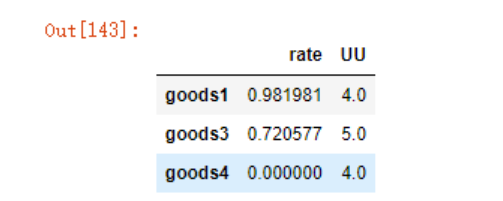
sim_u3= rating.sort_values(by="rate",
ascending=False)[:2].copy()
sim_u3
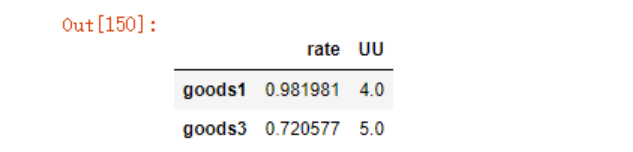
在pandas中计算向量很便捷
sim_u3.rate*sim_u3.UU

(sim_u3.rate*sim_u3.UU).sum()/(sim_u3.rate).sum()

参考https://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html