百度百科对TF-IDF的定义:TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF。
这个作者说的很透彻,文章链接在下方参考:
首先我们来了解一下什么是TF-IDF?
其实这个是两个词的组合,可以拆分为TF和IDF。
TF(Term Frequency,缩写为TF)也就是词频啦,即一个词在文中出现的次数,统计出来就是词频TF,显而易见,一个词在文章中出现很多次,那么这个词肯定有着很大的作用,但是我们自己实践的话,肯定会看到你统计出来的TF 大都是一些这样的词:‘的’,‘是’这样的词,这样的词显然对我们的分析和统计没有什么帮助,反而有的时候会干扰我们的统计,当然我们需要把这些没有用的词给去掉,现在有很多可以去除这些词的方法,比如使用一些停用词的语料库等。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,"蜜蜂"和"养殖"的重要程度要大于"中国",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
在机器学习当中,模型只能用于操作数值类型的数据,但如果我们想要处理文本,比如对文本分类,该怎样对文本数值化呢?
文本数值化的几种办法:
- one-hot编码
- 散列编码
- 词嵌入表示
- TF-IDF(经典机器学习)
在sklearn中已经为我们实现了这种算法,看下官方文档的参数
from sklearn.feature_extraction.text import TfidfVectorizer
Init signature:
TfidfVectorizer(
*,
input='content',
encoding='utf-8',
decode_error='strict',
strip_accents=None,
lowercase=True,
preprocessor=None,
tokenizer=None,
analyzer='word',
stop_words=None,
token_pattern='(?u)\\b\\w\\w+\\b',
ngram_range=(1, 1),
max_df=1.0,
min_df=1,
max_features=None,
vocabulary=None,
binary=False,
dtype=<class 'numpy.float64'>,
norm='l2',
use_idf=True,
smooth_idf=True,
sublinear_tf=False,
)
ngram_range 表示文档是如何被分词的。
stop_words 内建的停用词列表。
min_df 当构建词汇表时,严格忽略低于给出阈值的文档频率的词条,语料指定的停用词。
实例,利用TF-IDF搭建文本分类模型,数据为美国航空公司推特评论
data.head()
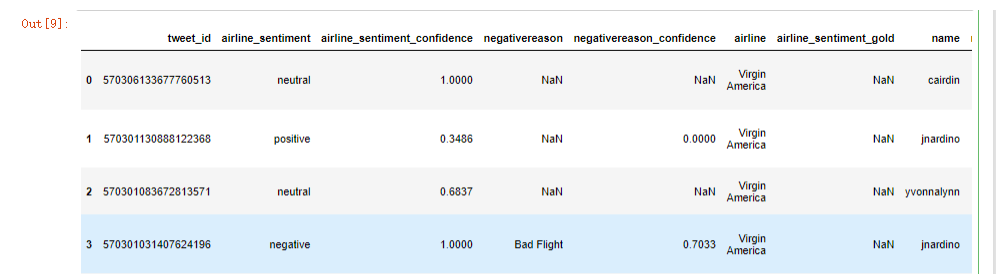
目的:预测评论的情绪是正面、负面还是中性。
df = data[['airline_sentiment','text']]
df
使用info查看下是否有空数据
df.info()
df.airline_sentiment.value_counts()

对于这种分类不均匀的数据,使用随机森林算法是一个很好的选择,而且使用随机森林还不需要对标签进行one hot编码,字符串标签毫无问题。
将文本进行预处理
pattern = re.compile(r'[a-zA-Z]+|[,.!?\s:()]')
def process_data(texts):
text = re.findall(pattern, texts)
text = "".join([x.lower() for x in text])
return text
x = df.text.apply(process_data)
x

y = df.airline_sentiment
此时就需要对训练数据进行向量化处理了,但是在这之前,我们应该先将训练、测试数据划分好,再进行向量化处理。
x_train,x_test,y_train,y_test = train_test_split(x,y)
x_train.shape

from sklearn.feature_extraction.text import TfidfVectorizer
# 开始向量化
vect = TfidfVectorizer(ngram_range=range(1,3),
stop_words=['english'],
min_df=2)
x_train_vect =vect.fit_transform(x_train)
x_train_vect

#test数据集上就不用fit_transform了
#因为test数据集上面我们不知道结果
x_test_vect = vect.transform(x_test)
x_test_vect

开始训练:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(x_train_vect, y_train)
model.score(x_train_vect,y_train)

model.score(x_test_vect,y_test)
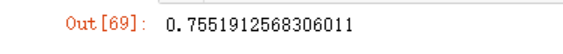
可以看到,明显过拟合了,使用GridSearchCV来进行交叉验证
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':range(100,110),
'max_depth':range(1,10),
'min_impurity_decrease':np.linspace(0,0.5)
}
model2 = GridSearchCV(RandomForestClassifier(n_jobs=3),
param_grid=params,
cv=5)
训练全部样本!不是前面划分的xtrain了,因此需要将所有数据向量化
#注意这里训练的就是全部样本了
x_vect =vect.fit_transform(x)
x_vect

model2.fit(x_vect,y)
参考:
https://blog.csdn.net/zhaomengszu/article/details/81452907